PHÃN
TÃCH NCA (NECESSARY CONDITION ANALYSIS) VÃ QUÃ TRÃNH XÃC ÄáŧNH CÃC ÄIáŧM NGášžN
(BOTTLENECK) SáŧŽ DáŧĪNG CÃNG CáŧĪ SMARTPLS
Bà i viášŋt nà y ÄÆ°áŧĢc xem là káŧđ thuášt nÃĒng cao, tiášŋp náŧi váŧi bà i
viášŋt váŧ káŧđ thuášt phÃĒn tÃch IPMA ÄÃĢ ÄÆ°áŧĢc chÚng tÃīi Äáŧ cášp trÆ°áŧc ÄÃģ (here).
Hiáŧn nay, Äa sáŧ cÃĄc nghiÊn cáŧĐu Äáŧnh lÆ°áŧĢng cháŧ dáŧŦng lᚥi áŧ cÃĒu
chuyáŧn phÃĒn tÃch háŧ sáŧ ÄÆ°áŧng dášŦn (beta) Äáŧ ÄÃĄnh giÃĄ máŧĐc Äáŧ tÃĄc Äáŧng cáŧ§a cÃĄc yášŋu
táŧ trong mÃī hÃŽnh lÊn biášŋn máŧĨc tiÊu (biášŋn pháŧĨ thuáŧc). Äáŧ táŧŦ ÄÃģ ÄÆ°a ra cÃĄc hà m Ã―
quášĢn tráŧ cᚧn thiášŋt. RášĨt Ãt cÃĄc nghiÊn cáŧĐu Äi sÃĒu và o phÃĒn tÃch NCA (Necessary
Condition Analysis) và tÃŽm cÃĄc Äiáŧm ngáš―n (bottlenecks) trong mÃī hÃŽnh
Äáŧnh lÆ°áŧĢng. CÃģ lášŧ, nguyÊn nhÃĒn cáŧ§a viáŧc nà y là do nháŧŊng phÆ°ÆĄng phÃĄp nà y yÊu cᚧu
sáŧą hiáŧu biášŋt sÃĒu hÆĄn váŧ káŧđ thuášt và cÃīng cáŧĨ phÃĒn tÃch. Trong nhiáŧu trÆ°áŧng háŧĢp,
viáŧc sáŧ dáŧĨng háŧ sáŧ ÄÆ°áŧng dášŦn ÄÃĢ Äáŧ§ Äáŧ tᚥo ra kášŋt luášn mang tÃnh hà m Ã― quášĢn tráŧ áŧ
máŧĐc Äáŧ táŧng quÃĄt, nÊn Ãt cÃģ Äáŧng láŧąc Äi sÃĒu hÆĄn.
NCA (Necessary Condition Analysis) là máŧt phÆ°ÆĄng phÃĄp dÃđng Äáŧ xÃĄc Äáŧnh cÃĄc Äiáŧu kiáŧn cᚧn thiášŋt (nhÆ°ng khÃīng Äáŧ§) trong nghiÊn cáŧĐu, táŧĐc là yášŋu táŧ mà nášŋu khÃīng Äᚥt ÄÆ°áŧĢc thÃŽ kášŋt quášĢ mong muáŧn sáš― khÃīng xášĢy ra. Káŧđ thuášt NCA ÄÆ°áŧĢc phÃĄt triáŧn ban Äᚧu báŧi Dul (2016).
PhÃĒn tÃch NCA khÃīng cháŧ tÃŽm kiášŋm cÃĄc yášŋu táŧ ášĢnh hÆ°áŧng mà cÃēn
xÃĄc Äáŧnh yášŋu táŧ cᚧn thiášŋt Äáŧ Äᚥt ÄÆ°áŧĢc kášŋt quášĢ máŧĨc tiÊu. Äiáŧu nà y giÚp cÃĄc bᚥn
xÃĄc Äáŧnh nháŧŊng Äiáŧu kiáŧn bášŊt buáŧc phášĢi ÄÃĄp áŧĐng trÆ°áŧc khi nÃģi Äášŋn viáŧc cášĢi thiáŧn
hiáŧu quášĢ hoáš·c tÄng tÃĄc Äáŧng cáŧ§a cÃĄc yášŋu táŧ khÃĄc. Ngoà i ra, TrÃĄnh lÃĢng phÃ
nguáŧn láŧąc, Bášąng cÃĄch nhášn diáŧn Äiáŧu kiáŧn cᚧn thiášŋt, nghiÊn cáŧĐu sáš― giÚp cho doanh
nghiáŧp cÃģ tháŧ trÃĄnh Äᚧu tÆ° và o cÃĄc yášŋu táŧ khÃīng phášĢi là cáŧt lÃĩi hoáš·c cháŧ tᚥo ra
giÃĄ tráŧ gia tÄng trong nháŧŊng Äiáŧu kiáŧn nhášĨt Äáŧnh.
Hᚥn chášŋ cáŧ§a viáŧc cháŧ tášp trung và o háŧ sáŧ ÄÆ°áŧng dášŦn cáŧ§a mÃī hÃŽnh SEM
âĒ Tášp trung và o máŧĐc Äáŧ tÃĄc Äáŧng nhÆ°ng báŧ qua tÃnh cᚧn thiášŋt: Háŧ sáŧ ÄÆ°áŧng dášŦn (Îē) Äo lÆ°áŧng máŧĐc Äáŧ và hÆ°áŧng tÃĄc Äáŧng giáŧŊa cÃĄc biášŋn nhÆ°ng khÃīng trášĢ láŧi cho cÃĒu háŧi âÄiáŧu gÃŽ là bášŊt buáŧc Äáŧ kášŋt quášĢ xášĢy ra?â. Viáŧc khÃīng phÃĒn tÃch cÃĄc yášŋu táŧ cᚧn thiášŋt cÃģ tháŧ dášŦn Äášŋn thiášŋu sÃģt trong viáŧc nhášn diáŧn cÃĄc yášŋu táŧ cáŧt lÃĩi mà nášŋu khÃīng tháŧa mÃĢn, biášŋn máŧĨc tiÊu sáš― khÃīng Äᚥt ÄÆ°áŧĢc.
âĒ Thiášŋu cÃĄi nhÃŽn toà n diáŧn: PhÃĒn tÃch cháŧ tášp trung và o beta thÆ°áŧng mang tÃnh tuyášŋn tÃnh và khÃīng phášĢn ÃĄnh ÄÆ°áŧĢc sáŧą pháŧĐc tᚥp cáŧ§a máŧi quan háŧ giáŧŊa cÃĄc yášŋu táŧ, Äáš·c biáŧt váŧi cÃĄc mÃī hÃŽnh SEM pháŧĐc tᚥp.
âĒ KhÃīng phÃĄt hiáŧn ÄÆ°áŧĢc Äiáŧm ngháš―n (bottleneck): CÃĄc yášŋu táŧ hᚥn chášŋ hiáŧu quášĢ cáŧ§a mÃī hÃŽnh khÃīng ÄÆ°áŧĢc nhášn diáŧn. Äiáŧu nà y cÃģ tháŧ dášŦn Äášŋn viáŧc báŧ qua cÃĄc rà o cášĢn tiáŧm ášĐn trong quÃĄ trÃŽnh cášĢi tiášŋn mÃī hÃŽnh.
Äáŧ ÄÃĄnh giÃĄ NCA chÚng ta cᚧn dáŧąa và o cÃĄc tiÊu chà sau:
* Effect Size (d):
KÃch thÆ°áŧc hiáŧu áŧĐng (effect size) trong NCA ÄÆ°áŧĢc Äo bášąng
táŧ· láŧ giáŧŊa vÃđng tráŧng phÃa trÊn ÄÆ°áŧng ceiling (ceiling zone) so váŧi táŧng vÃđng dáŧŊ
liáŧu khášĢ thi (scope). Quy tášŊc ÄÃĄnh giÃĄ ÄÆ°áŧĢc trÃch dášŦn báŧi
âĒ 0 < d < 0.1: Hiáŧu áŧĐng nháŧ (small effect).
âĒ 0.1 âĪ d < 0.3: Hiáŧu áŧĐng trung bÃŽnh (medium effect).
âĒ 0.3 âĪ d < 0.5: Hiáŧu áŧĐng láŧn (large effect).
âĒ d âĨ 0.5: Hiáŧu áŧĐng rášĨt láŧn (very large effect).
ÄÃĄnh giÃĄ kÃch thÆ°áŧc hiáŧu áŧĐng pháŧĨ thuáŧc và o báŧi cášĢnh nghiÊn cáŧĐu, nhÆ°ng máŧĐc ngÆ°áŧĄng d âĨ 0.1 thÆ°áŧng ÄÆ°áŧĢc sáŧ dáŧĨng nhÆ° máŧt chuášĐn Äáŧ xem xÃĐt tÃnh cᚧn thiášŋt cáŧ§a Äiáŧu kiáŧn. Váŧi cÃĄc biášŋn cÃģ d < 0.1, chÚng ta khÃīng nÊn Æ°u tiÊn tášp trung nguáŧn láŧąc và o nÃģ.
* Accuracy: Tháŧ hiáŧn Äáŧ chÃnh xÃĄc cáŧ§a mÃī hÃŽnh trong viáŧc dáŧą ÄoÃĄn cÃĄc giÃĄ
tráŧ ceiling (giáŧi hᚥn trÊn). GiÃĄ tráŧ 100% cho thášĨy rášąng tášĨt cášĢ cÃĄc Äiáŧm dáŧŊ liáŧu
Äáŧu nášąm dÆ°áŧi hoáš·c trÊn ÄÆ°áŧng ceiling, cháŧĐng minh mÃī hÃŽnh hoᚥt Äáŧng táŧt.
* Condition inefficiency: XÃĄc Äáŧnh cÃĄc giÃĄ tráŧ cáŧ§a Äiáŧu kiáŧn vÆ°áŧĢt máŧĐc cᚧn thiášŋt
(và dáŧĨ: nášŋu X > Xc,max thÃŽ máŧĐc tÄng cáŧ§a X
khÃīng cÃēn cᚧn thiášŋt cho Y).
* Outcome inefficiency: XÃĄc Äáŧnh cÃĄc máŧĐc Äáŧ cáŧ§a kášŋt quášĢ thášĨp hÆĄn Yc,min â, nÆĄi mà X khÃīng báŧ rà ng buáŧc
báŧi Y.
* Relative Inefficiency: Kášŋt háŧĢp cášĢ condition inefficiency và outcome
inefficiency Äáŧ Äo lÆ°áŧng hiáŧu quášĢ táŧng tháŧ.
* Absolute Inefficiency: Äo lÆ°áŧng táŧng máŧĐc Äáŧ khÃīng hiáŧu quášĢ tuyáŧt Äáŧi cáŧ§a Äiáŧu
kiáŧn.
TáŧŦ nháŧŊng thÃīng tin hoáš·c kášŋt quášĢ phÃĒn tÃch NCA, chÚng ta cÃģ tháŧ
chuyáŧn hÃģa thà nh hà nh Äáŧng cáŧĨ tháŧ (Actionable insights) nhášąm giášĢi quyášŋt
máŧt vášĨn Äáŧ hoáš·c cášĢi thiáŧn máŧt tÃŽnh huáŧng. VÃ dáŧĨ, nášŋu phÃĒn tÃch dáŧŊ liáŧu cho thášĨy
rášąng khÃĄch hà ng ráŧi báŧ dáŧch váŧĨ do tháŧi gian phášĢn háŧi chášm, actionable insight sáš―
là : âCᚧn giášĢm tháŧi gian phášĢn háŧi khÃĄch hà ng xuáŧng dÆ°áŧi 10 phÚt.â
QuÃĄ trÃŽnh phÃĒn tÃch NCA cᚧn xÃĄc Äáŧnh cÃĄc Äiáŧm ngháš―n (bottleneck)
là m ášĢnh hÆ°áŧng Äášŋn biášŋn máŧĨc tiÊu, gÃĒy cášĢn tráŧ hiáŧu suášĨt táŧng tháŧ. Và dáŧĨ: Trong sášĢn
xuášĨt, máŧt mÃĄy mÃģc chášm hÆĄn cÃĄc mÃĄy khÃĄc là bottleneck, khiášŋn toà n báŧ quy trÃŽnh
báŧ chášm lᚥi, chÚng ta cᚧn tÃŽm cÃĄch cášĢi tiášŋn báŧ mÃĄy nà y. Nášŋu háŧ tháŧng dáŧch
váŧĨ khÃĄch hà ng báŧ chášm tráŧ
do thiášŋu nhÃĒn sáŧą, bottleneck analysis sáš― Äáŧ xuášĨt tÄng
cÆ°áŧng nhÃĒn viÊn hoáš·c táŧą Äáŧng hÃģa máŧt sáŧ quy trÃŽnh. ÄÃĒy ÄÆ°áŧĢc xem nhÆ° là giášĢi
phÃĄp Äáŧ loᚥi báŧ hoáš·c giášĢm thiáŧu tÃĄc Äáŧng cáŧ§a Äiáŧm ngháš―n.
NhÆ° vášy, cuáŧi cÃđng cáŧ§a phÃĒn tÃch NCA là tÃŽm cÃĄch chÃnh xÃĄc nhášĨt
Äáŧ chuyáŧn Äáŧi kášŋt quášĢ thà nh actionable insights. Bášąng cÃĄch, Nhášn diáŧn
bottleneck: XÃĄc Äáŧnh biášŋn nà o cÃģ ášĢnh hÆ°áŧng mᚥnh nhášĨt và là Äiáŧu kiáŧn cᚧn
thiášŋt. Sau ÄÃģ, Äáŧ xuášĨt hà nh Äáŧng: CášĢi thiáŧn yášŋu táŧ bottleneck Äáŧ Äᚥt giÃĄ
tráŧ cᚧn thiášŋt.
|
HÃ nh Äáŧng |
Khi nà o tháŧąc hiáŧn |
MáŧĨc tiÊu chÃnh |
à nghÄĐa |
|
TÄng cÆ°áŧng (Enhance) |
Yášŋu táŧ quan tráŧng, cᚧn
máŧ ráŧng tÃĄc Äáŧng Äáŧ Äᚥt máŧĨc tiÊu láŧn hÆĄn. |
ThÚc ÄášĐy yášŋu táŧ lÊn máŧĐc
cao hÆĄn. |
Khi yášŋu táŧ quan tráŧng vÃ
cᚧn máŧ ráŧng Äáŧ ÄÃĄp áŧĐng máŧĨc tiÊu láŧn. |
|
Duy trÃŽ (Maintain) |
Yášŋu táŧ ÄÃĢ hiáŧu quášĢ, cᚧn
ÄášĢm bášĢo áŧn Äáŧnh, khÃīng báŧ suy giášĢm. |
GiáŧŊ áŧn Äáŧnh giÃĄ tráŧ hiáŧn
tᚥi. |
Khi yášŋu táŧ ÄÃĢ Äáŧ§ và cᚧn
áŧn Äáŧnh. |
|
Táŧi Æ°u (Optimize) |
Yášŋu táŧ cÃģ inefficiency
cao, cᚧn giášĢm lÃĢng phà và nÃĒng cao hiáŧu quášĢ. |
Loᚥi báŧ lÃĢng phÃ, nÃĒng
cao hiáŧu suášĨt. |
Khi yášŋu táŧ chÆ°a hiáŧu
quášĢ, cᚧn tinh cháŧnh. |
|
CášĢi thiáŧn (Improve) |
Yášŋu táŧ yášŋu, khÃīng Äᚥt
yÊu cᚧu, cᚧn ÄÆ°a lÊn máŧĐc chášĨp nhášn ÄÆ°áŧĢc hoáš·c táŧt hÆĄn. |
NÃĒng cášĨp yášŋu táŧ táŧŦ yášŋu
sang mᚥnh hoáš·c chášĨp nhášn ÄÆ°áŧĢc. |
Khi yášŋu táŧ yášŋu kÃĐm, cᚧn
nÃĒng cášĨp Äáŧ Äᚥt yÊu cᚧu. |
CÃĄc phÆ°ÆĄng phÃĄp CE-FDH và CR-FDH (Hai loᚥi ÄÆ°áŧng ceiling pháŧ biášŋn)
âĒ CE-FDH (Ceiling Envelopment-Free Disposal Hull): ÄÆ°áŧng bášc thang tuyášŋn tÃnh khÃīng giášĢm
+ PhÆ°ÆĄng phÃĄp nà y sáŧ dáŧĨng tiášŋp cášn bao báŧc (envelopment) Äáŧ tᚥo ra máŧt giáŧi hᚥn ceiling. NÃģ phÃđ háŧĢp khi bᚥn muáŧn phÃĒn tÃch cÃĄc Äiáŧu kiáŧn máŧt cÃĄch táŧą do mà khÃīng ÃĄp dáŧĨng mÃī hÃŽnh háŧi quy. PhÃđ háŧĢp váŧi dáŧŊ liáŧu ráŧi rᚥc (LÆ°u Ã―, thang Äo Likert cÅĐng là máŧt dᚥng thang Äo ráŧi rᚥc). LÆ°u Ã―, viáŧc chuyáŧn Äáŧi sang biášŋn tiáŧm ášĐn (Latent Variable - LV) khÃīng là m thay Äáŧi Äáš·c Äiáŧm cáŧ§a thang Äo Äᚧu và o. NÊn thang Äo Likert dÃđ cÃģ chuášĐn hÃģa thÃŽ nÃģ vášŦn cÃģ Äáš·c Äiáŧm cáŧ§a máŧt thang Äo ráŧi rᚥc váŧ máš·t dáŧŊ liáŧu.
+ ÆŊu Äiáŧm: PhÃđ háŧĢp váŧi dáŧŊ liáŧu nháŧ hoáš·c khÃīng tuyášŋn tÃnh, nhášĨn mᚥnh và o cÃĄc Äiáŧu kiáŧn cᚧn thiášŋt máŧt cÃĄch táŧng quÃĄt.
+ NhÆ°áŧĢc Äiáŧm: CÃģ tháŧ hÆĄi âcháš·t cháš―â vÃŽ tᚥo ceiling line rášĨt sÃĄt váŧi dáŧŊ liáŧu.
âĒ CR-FDH (Ceiling Regression-Free Disposal Hull): ÄÆ°áŧng háŧi quy tuyášŋn tÃnh ÄÆĄn giášĢn Äi qua cÃĄc Äiáŧm dáŧŊ liáŧu cáŧ§a ÄÆ°áŧng CE-FDH
+ PhÆ°ÆĄng phÃĄp nà y kášŋt háŧĢp háŧi quy váŧi mÃī hÃŽnh Free Disposal Hull. Ceiling line ÄÆ°áŧĢc thiášŋt lášp dáŧąa trÊn háŧi quy, thÆ°áŧng phÃđ háŧĢp váŧi dáŧŊ liáŧu tuyášŋn tÃnh hoáš·c khi bᚥn cᚧn phÃĒn tÃch chÃnh xÃĄc hÆĄn. PhÃđ háŧĢp váŧi dáŧŊ liáŧu liÊn táŧĨc.
+ ÆŊu Äiáŧm: PhÃđ háŧĢp váŧi cÃĄc mÃī hÃŽnh pháŧĐc tᚥp, tᚥo ra ceiling line máŧm mᚥi hÆĄn.
+ NhÆ°áŧĢc Äiáŧm: CÃģ tháŧ khÃīng phÃđ háŧĢp khi dáŧŊ liáŧu rášĨt phi tuyášŋn tÃnh.
CÃĄch cháŧn:
Viáŧc láŧąa cháŧn giáŧŊa CE-FDH và CR-FDH cᚧn dáŧąa trÊn bášĢn chášĨt cáŧ§a dáŧŊ liáŧu (ráŧi rᚥc hay liÊn táŧĨc).
âĒ ÄÆ°áŧng CE-FDH ÄÆ°áŧĢc khuyášŋn ngháŧ sáŧ dáŧĨng cho dáŧŊ liáŧu ráŧi rᚥc.
âĒ ÄÆ°áŧng CR-FDH ÄÆ°áŧĢc khuyášŋn ngháŧ sáŧ dáŧĨng cho dáŧŊ liáŧu liÊn táŧĨc.
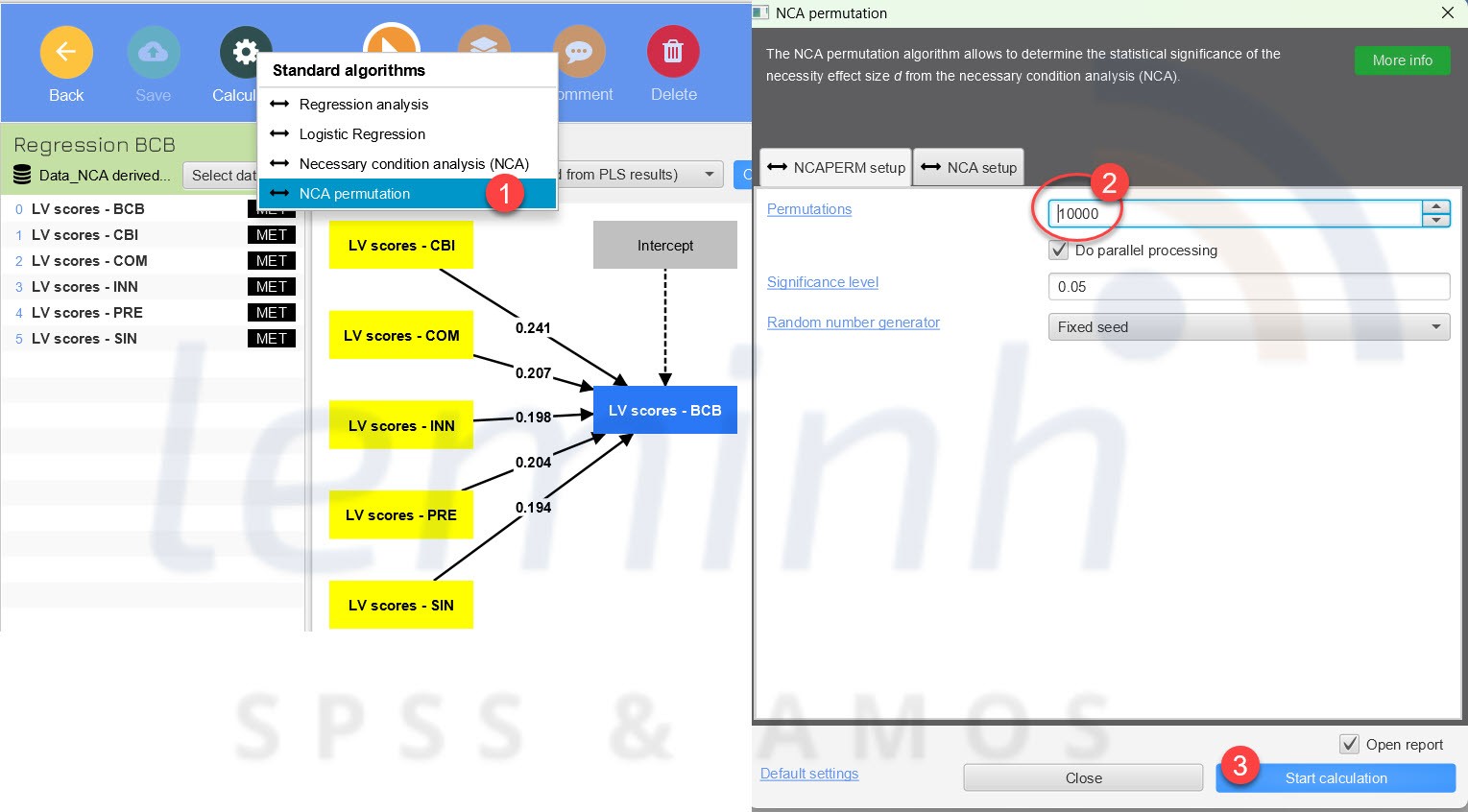
NCA Permutation
MáŧĨc ÄÃch là Kiáŧm tra Äáŧ tin cášy (permutation test). NCA Permutation tháŧąc hiáŧn
cÃĄc phÃĐp tháŧ ngášŦu nhiÊn Äáŧ kiáŧm tra xem kášŋt quášĢ táŧŦ phÃĒn tÃch NCA cÃģ tháŧąc sáŧą Ã―
nghÄĐa hay khÃīng.
CÃĄch tháŧąc hiáŧn cáŧ§a kiáŧm Äáŧnh nà y là chÆ°ÆĄng trÃŽnh sáš― thay Äáŧi
ngášŦu nhiÊn tháŧĐ táŧą cáŧ§a cÃĄc giÃĄ tráŧ trong tášp dáŧŊ liáŧu. Sau ÄÃģ, so sÃĄnh kášŋt quášĢ giáŧŊa
dáŧŊ liáŧu gáŧc và dáŧŊ liáŧu hoÃĄn Äáŧi. Và , xÃĄc Äáŧnh xem hiáŧu áŧĐng cáŧ§a Äiáŧu kiáŧn cᚧn
thiášŋt cÃģ phášĢi là do ngášŦu nhiÊn hay khÃīng. Nášŋu P-value nháŧ hÆĄn máŧĐc Ã― nghÄĐa tháŧng
kÊ thÃŽ kášŋt luášn, phÃĒn tÃch NCA Äᚥt yÊu cᚧu váŧ Äáŧ tin cášy.
Tháŧąc hà nh
BÃĒy giáŧ, chÚng ta sáš― Äi chi tiášŋt và o phᚧn tháŧąc hà nh phÃĒn tÃch NCA bášąng SmartPLS 4. CÃĄc bᚥn lÆ°u Ã― rášąng, NCA khÃīng chᚥy tráŧąc tiášŋp trÊn model SEM nhÃĐ. Káŧđ thuášt NCA ÄÆ°áŧĢc ÄÃĄnh giÃĄ trÊn Regession model (mÃī hÃŽnh háŧi qui Äa biášŋn). ChÃnh vÃŽ vášy, trong mÃī hÃŽnh PLS SEM hay CB SEM cÃĄc bᚥn sáš― khÃīng thášĨy NCA trong SmartPLS.
LÆ°u Ã―, khi tháŧąc hiáŧn NCA, hÃĢy ÄášĢm bášĢo rášąng thang Äo cáŧ§a cÃĄc cháŧ sáŧ cáŧ§a bᚥn nhÆ° mong ÄáŧĢi. Và dáŧĨ, thang Äo khoášĢng cÃĄch táŧŦ 1 Äášŋn 7 phášĢi hiáŧn tháŧ giÃĄ tráŧ táŧi thiáŧu là 1 và giÃĄ tráŧ táŧi Äa là 7 (và dáŧĨ, Äiáŧu nà y cÃģ tháŧ khÃīng ÄÚng nášŋu khÃīng cÃģ ngÆ°áŧi trášĢ láŧi nà o cháŧn 1). Äiáŧu nà y rášĨt quan tráŧng Äáŧ ÄášĢm bášĢo tÃnh chÃnh xÃĄc cáŧ§a kášŋt quášĢ.
CÃĄc bᚥn cÃģ tháŧ tášĢi báŧ dáŧŊ liáŧu mášŦu tᚥi ÄÃĒy.
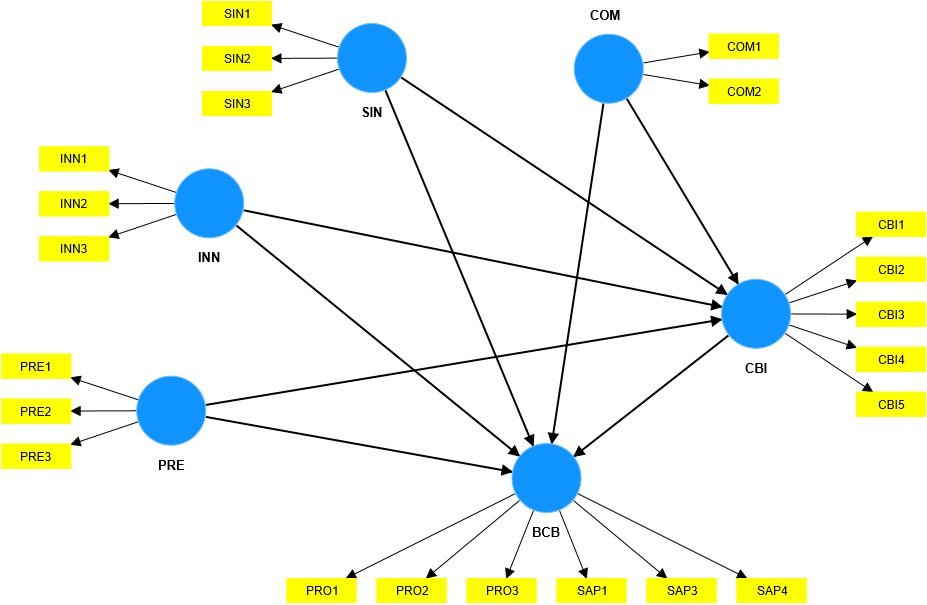
BÆ°áŧc 1: ÄÃĄnh giÃĄ mÃī hÃŽnh Äo lÆ°áŧng, cÃĄc bÆ°áŧc ÄÃĄnh giÃĄ chÚng tÃīi khÃīng trÃŽnh bà y lᚥi
áŧ ÄÃĒy. CÃĄc bᚥn cÃģ tháŧ tham khášĢo tᚥi bà i viášŋt trÆ°áŧc áŧ ÄÃĒy.
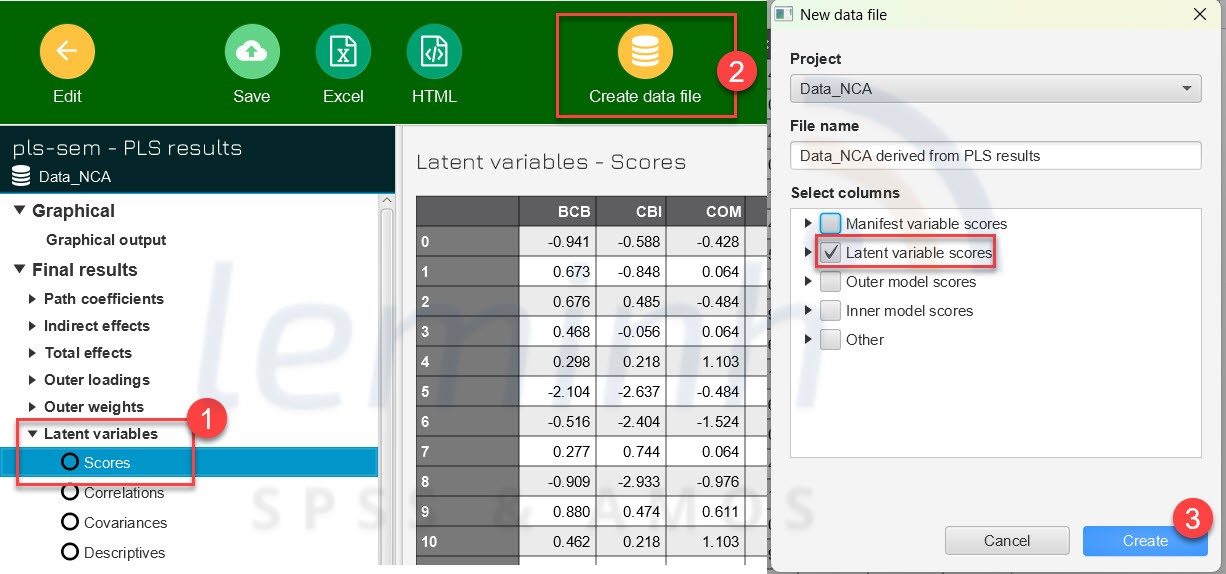
BÆ°áŧc 2: Tᚥo dáŧŊ liáŧu Äáŧ chᚥy NCA táŧŦ Latent Variables Scores.
BÆ°áŧc 3: XÃĒy dáŧąng mÃī hÃŽnh háŧi qui Äáŧ chᚥy NCA. Váŧi mÃī hÃŽnh mášŦu nà y, chÚng ta thášĨy
cÃģ 2 biášŋn náŧi sinh (Endogenous Variable) và 4 biášŋn ngoᚥi sinh (Exogenous
Variable). Do ÄÃģ, chÚng ta sáš― tᚥo ra 2 model háŧi qui nhÆ° sau:
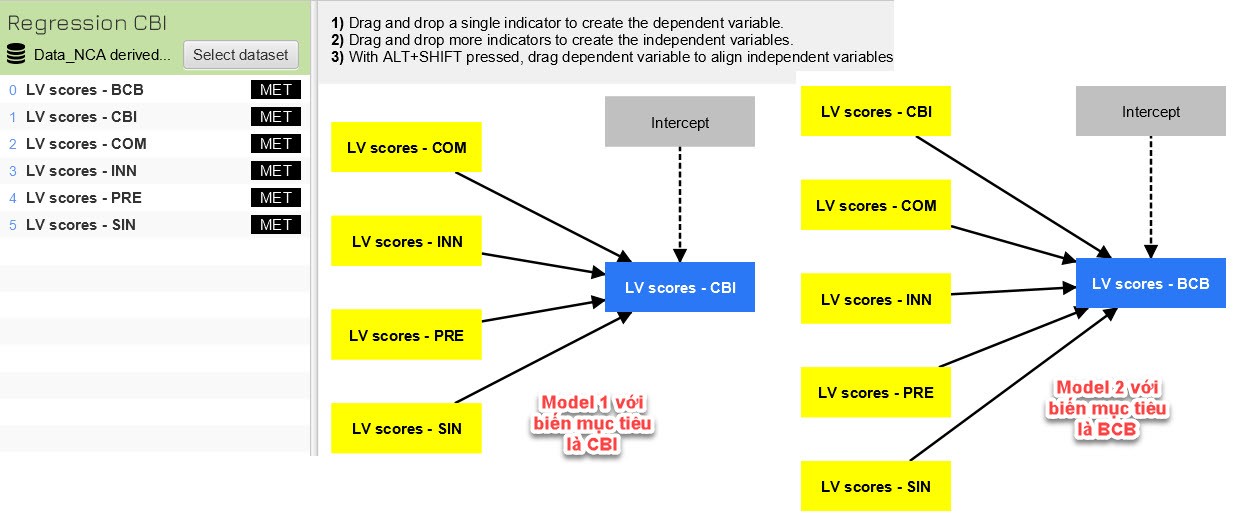
Dáŧąa theo máŧĨc tiÊu nghiÊn cáŧĐu mà cÃĄc bᚥn nÊn cháŧn mÃī hÃŽnh 1 hoáš·c 2 hoáš·c cášĢ hai mÃī hÃŽnh Äáŧ phÃĒn tÃch. áŧ ÄÃĒy, chÚng tÃīi sáŧ dáŧĨng mÃī hÃŽnh sáŧ 2 Äáŧ phÃĒn tÃch, váŧi biášŋn máŧĨc tiÊu là BCB.
Thuášt toÃĄn phÃĒn tÃch Äiáŧu kiáŧn cᚧn thiášŋt (NCA) cho cÃĄc mÃī hÃŽnh háŧi quy trong SmartPLS cháŧ yÊu cᚧu máŧt thiášŋt lášp tham sáŧ duy nhášĨt, ÄÃģ là Sáŧ bÆ°áŧc cho cÃĄc bášĢng nÚt thášŊt . Do ÄÃģ, bᚥn cÃģ tháŧ cháŧ Äáŧnh sáŧ bÆ°áŧc mà biášŋn pháŧĨ thuáŧc ÄÆ°áŧĢc chia thà nh cÃĄc bášĢng nÚt thášŊt cáŧ§a NCA. GiÃĄ tráŧ máš·c Äáŧnh là 10, chia kášŋt quášĢ hiáŧn tháŧ thà nh 10% bÆ°áŧc táŧŦ 0% Äášŋn 100%. Tuy nhiÊn, bᚥn cÅĐng cÃģ tháŧ cháŧn hiáŧn tháŧ kášŋt quášĢ chi tiášŋt hÆĄn. Và dáŧĨ: giÃĄ tráŧ 20 chia kášŋt quášĢ thà nh 5% bÆ°áŧc táŧŦ 0% Äášŋn 100%.
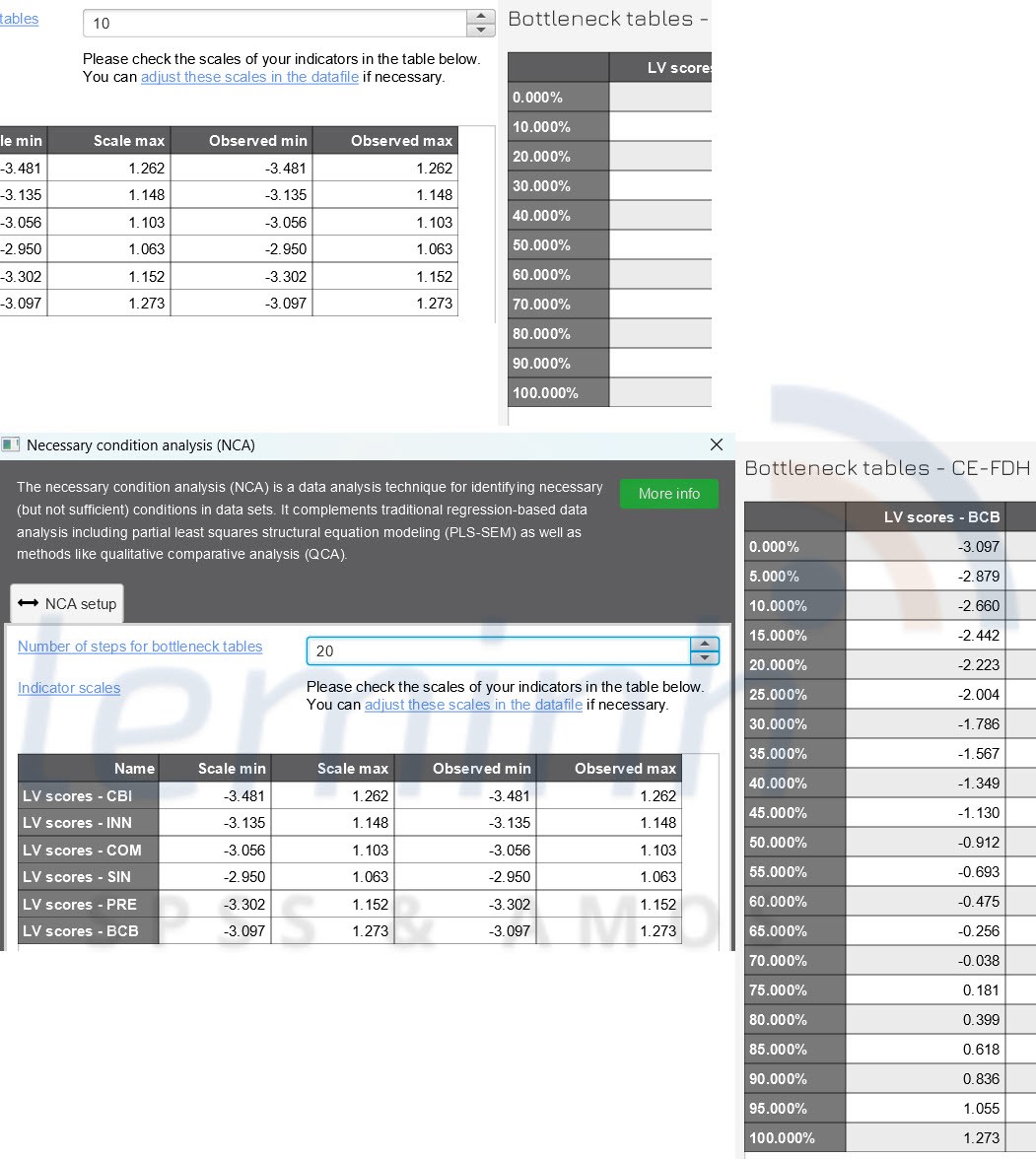
CÃĄc bᚥn cháŧn Necessary Condition Analysis (NCA), Äáŧ máš·c Äáŧnh
và nhášĨn Start calculation.

Äáŧc kášŋt quášĢ NCA
 (Nguáŧn: Smartpls.com)
(Nguáŧn: Smartpls.com)
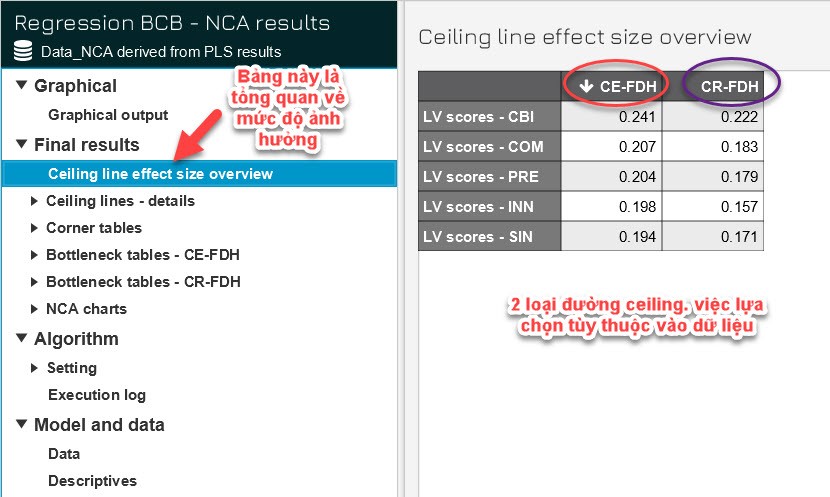
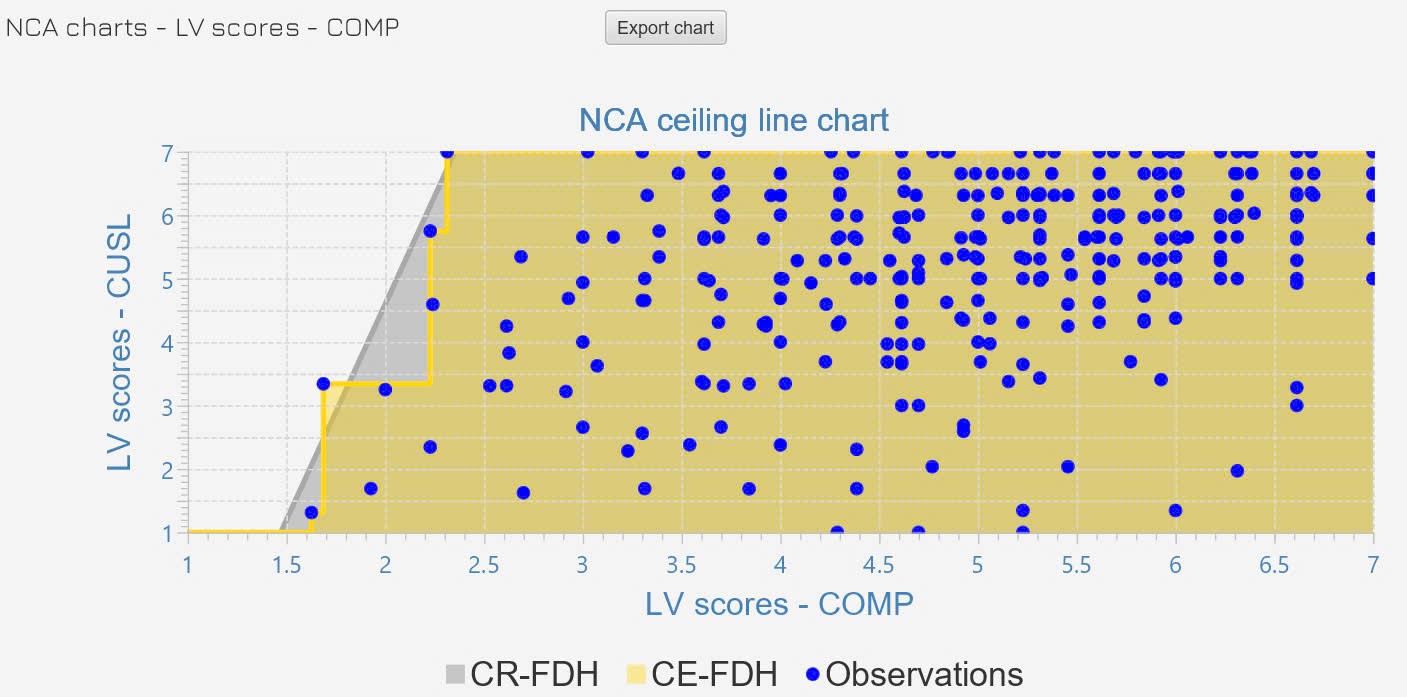
VÃŽ dáŧŊ liáŧu cáŧ§a chÚng ta sáŧ dáŧĨng Likert nÊn ÄÆ°áŧng ceiling CE-FDH
sáš― ÄÆ°áŧĢc sáŧ dáŧĨng trong nghiÊn cáŧĐu nà y.
Cáŧt CE-FDH trong bášĢng Ceiling line effect size overview tháŧ
hiáŧn máŧĐc Äáŧ cáŧ§a cÃĄc biášŋn tiáŧm ášĐn (LV score) khi ÃĄp dáŧĨng phÆ°ÆĄng phÃĄp CE-FDH. ÄÃĒy
là máŧt phÆ°ÆĄng phÃĄp Äáŧ váš― ÄÆ°áŧng ceiling nhášąm xÃĄc Äáŧnh vÃđng tráŧng (empty zone)
trong dáŧŊ liáŧu, nÆĄi mà Äiáŧu kiáŧn ÄÆ°áŧĢc coi là cᚧn thiášŋt cho kášŋt quášĢ mong muáŧn. CE-FDH
tᚥo ra cÃĄc ÄÆ°áŧng ceiling dᚥng bášc thang (piecewise linear), bao quanh dáŧŊ liáŧu
mà khÃīng cho phÃĐp bášĨt káŧģ Äiáŧm nà o nášąm trÊn ÄÆ°áŧng ceiling. GiÃĄ tráŧ trong cáŧt nà y
ÄÆ°áŧĢc tÃnh toÃĄn dáŧąa trÊn táŧ· láŧ giáŧŊa vÃđng tráŧng phÃa trÊn ÄÆ°áŧng ceiling (ceiling
zone) so váŧi táŧng vÃđng dáŧŊ liáŧu khášĢ thi (scope).

Nguáŧn: Dul (2016)
TáŧŦ kášŋt quášĢ phÃĒn tÃch effect size, tášĨt cášĢ cÃĄc biášŋn Äáŧu cÃģ tÃĄc
Äáŧng ÄÃĄng káŧ Äášŋn BCB váŧi giÃĄ tráŧ effect size láŧn hÆĄn 0.1. Trong ÄÃģ, CBI
tháŧ hiáŧn ášĢnh hÆ°áŧng mᚥnh nhášĨt váŧi effect size là 0.241, tiášŋp theo là COM
(0.207) và PRE (0.204). Hai biášŋn cÃēn lᚥi là INN (0.198) và SIN
(0.194) cÅĐng cÃģ máŧĐc ášĢnh hÆ°áŧng trung bÃŽnh ÄÃĄng káŧ. Sáŧą chÊnh láŧch giáŧŊa cÃĄc biášŋn
khÃīng quÃĄ láŧn, cho thášĨy tášĨt cášĢ Äáŧu ÄÃģng vai trÃē quan tráŧng trong viáŧc tÃĄc Äáŧng
Äášŋn biášŋn máŧĨc tiÊu BCB.
Äáŧ ÄÃĄnh giÃĄ chi tiášŋt váŧ Äiáŧu kiáŧn cᚧn, chÚng ta qua bášĢng
Ceiling lines â details
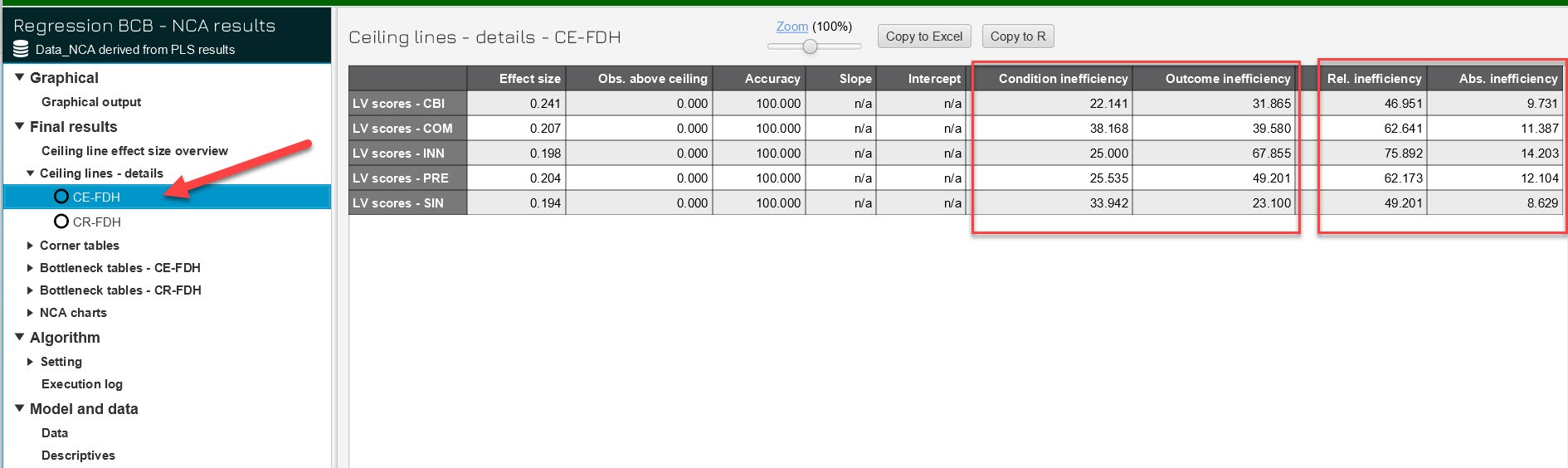
Cáŧt Accuracy (Äáŧ chÃnh xÃĄc) tháŧ hiáŧn Äáŧ tin cášy cáŧ§a
phÃĒn tÃch. GiÃĄ tráŧ 100% áŧ tášĨt cášĢ cÃĄc biášŋn cho thášĨy kášŋt quášĢ phÃĒn tÃch rášĨt ÄÃĄng
tin cášy.
Kášŋt háŧĢp váŧi kášŋt quášĢ phÃĒn tÃch Äiáŧm ngáš―n
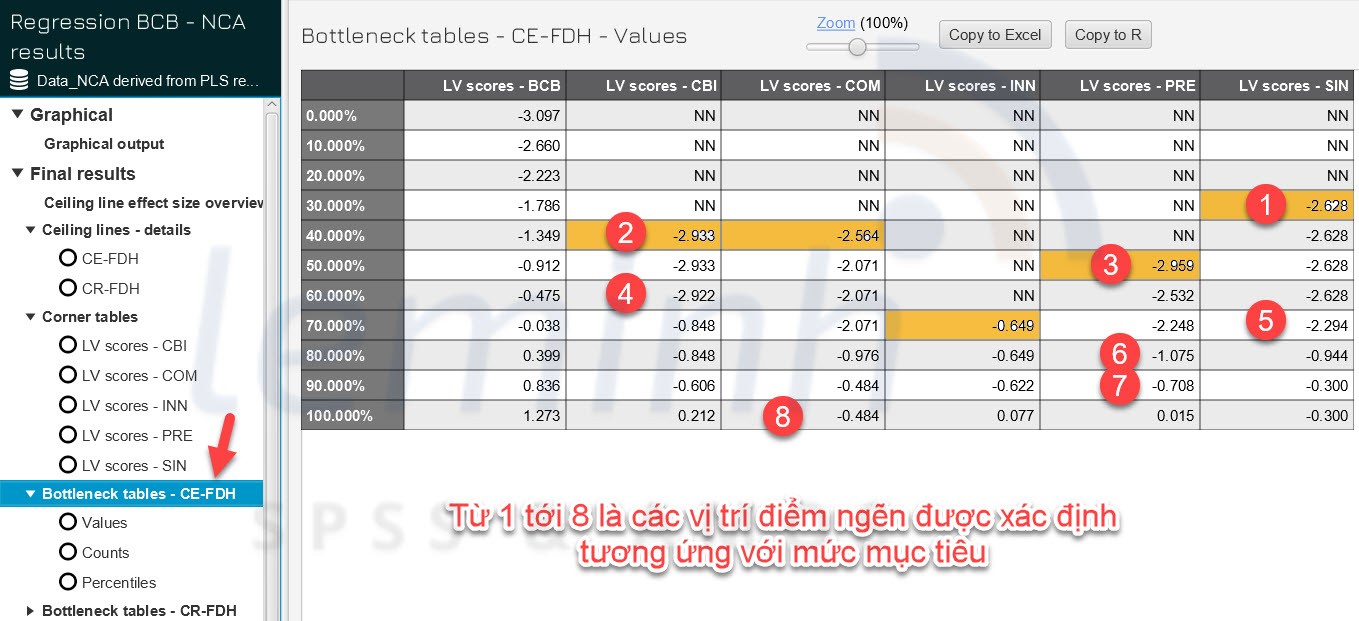
|
MáŧĐc máŧĨc tiÊu |
Bottleneck chÃnh |
Kášŋt quášĢ táŧŦ bášĢng
bottleneck |
PhÃĒn tÃch táŧŦ bášĢng
Ceiling line |
HÃ nh Äáŧng gáŧĢi Ã― |
|
100% |
COM |
GiÃĄ tráŧ thášĨp nhášĨt:
-0.484 |
COM cÃģ Condition inefficiency cao nhášĨt (38.168),
cᚧn cášĢi thiáŧn mᚥnh Äᚧu và o Äáŧ giášĢm tÃĄc Äáŧng tiÊu cáŧąc áŧ máŧĐc máŧĨc tiÊu cao. |
- CášĢi thiáŧn quy trÃŽnh là m viáŧc, giášĢm lÃĢng phà trong sáŧ
dáŧĨng nguáŧn láŧąc. |
|
- TÄng cÆ°áŧng cÃīng cáŧĨ quášĢn lÃ― Äáŧ ÄášĢm bášĢo hiáŧu quášĢ Äᚧu và o. |
||||
|
- Äà o tᚥo káŧđ nÄng quášĢn lÃ― và háŧĢp tÃĄc giáŧŊa cÃĄc báŧ phášn. |
||||
|
90% |
PRE |
GiÃĄ tráŧ thášĨp nhášĨt:
-0.708 |
PRE cÃģ Relative inefficiency cao (62.173), cho
thášĨy sáŧą mášĨt cÃĒn Äáŧi giáŧŊa Äᚧu và o và kášŋt quášĢ. |
- NÃĒng cao chášĨt lÆ°áŧĢng xáŧ lÃ― Äᚧu và o thÃīng qua táŧą Äáŧng hÃģa
hoáš·c Äà o tᚥo thÊm nhÃĒn sáŧą. |
|
- TÄng táŧc Äáŧ xáŧ lÃ― và giÃĄm sÃĄt cháš·t cháš― quÃĄ trÃŽnh Äáŧ
giášĢm lÃĢng phà tà i nguyÊn Äᚧu và o. |
||||
|
80% |
PRE |
GiÃĄ tráŧ thášĨp nhášĨt:
-1.075 |
PRE tiášŋp táŧĨc là yášŋu táŧ ngháš―n, váŧi Absolute
inefficiency cao (12.104). |
- PhÃĒn báŧ thÊm nguáŧn láŧąc Äáŧ giášĢm lÃĢng phà Äᚧu ra. |
|
- XÃĒy dáŧąng cÃĄc giášĢi phÃĄp táŧi Æ°u hÃģa quy trÃŽnh vášn hà nh
liÊn quan Äášŋn yášŋu táŧ PRE. |
||||
|
70% |
SIN |
GiÃĄ tráŧ thášĨp nhášĨt:
-2.294 |
SIN cÃģ Condition inefficiency cao (33.942), nhÆ°ng
táŧng máŧĐc Äáŧ khÃīng hiáŧu quášĢ (Relative inefficiency: 49.201) thášĨp hÆĄn cÃĄc yášŋu
táŧ khÃĄc. |
- ÄášĢm bášĢo tÃnh nhášĨt quÃĄn trong quy trÃŽnh liÊn quan Äášŋn
SIN. |
|
- Sáŧ dáŧĨng cÃĄc cÃīng cáŧĨ giÃĄm sÃĄt chášĨt lÆ°áŧĢng Äáŧ cášĢi thiáŧn
tÃnh Äáŧng nhášĨt và hiáŧu quášĢ. |
||||
|
60% |
CBI |
GiÃĄ tráŧ thášĨp nhášĨt:
-2.922 |
CBI cÃģ Effect size cao nhášĨt (0.241), cho thášĨy ÄÃĒy
là yášŋu táŧ rášĨt quan tráŧng Äáŧ Äᚥt hiáŧu quášĢ táŧng tháŧ. Tuy nhiÊn, khÃīng hiáŧu quášĢ
Äᚧu và o tÆ°ÆĄng Äáŧi thášĨp. |
- TÄng cÆ°áŧng cÃĄc nÄng láŧąc liÊn quan Äášŋn yášŋu táŧ CBI (vÃ
dáŧĨ: cášĢi tiášŋn Äà o tᚥo, phÃĒn báŧ nguáŧn láŧąc). |
|
- ÄášĢm bášĢo yášŋu táŧ nà y khÃīng báŧ giášĢm hiáŧu quášĢ thÊm áŧ cÃĄc
máŧĐc máŧĨc tiÊu cao hÆĄn. |
Kiáŧm Äáŧnh máŧĐc Äáŧ tin cášy cáŧ§a kášŋt quášĢ phÃĒn tÃch NCA
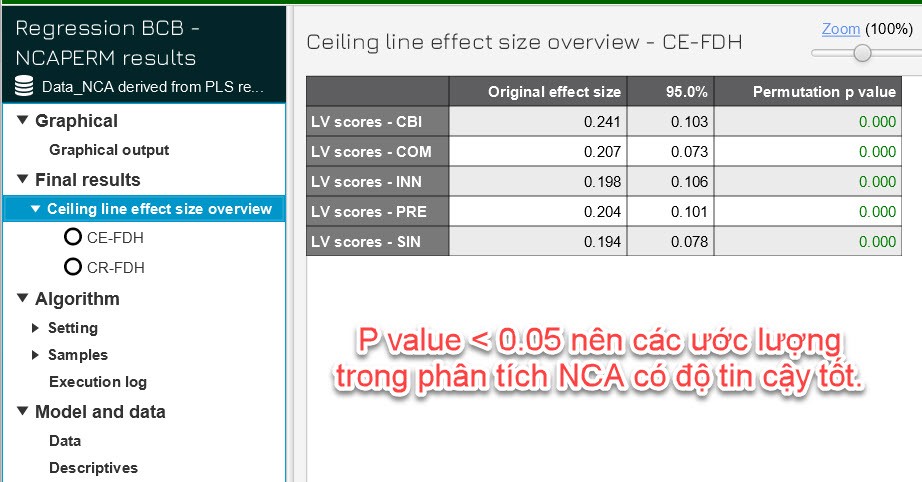
Kášŋt luášn:
CBI là biášŋn quan tráŧng nhášĨt vÃŽ nÃģ cÃģ effect size láŧn nhášĨt (0.241) và máŧĐc
khÃīng hiáŧu quášĢ tÆ°ÆĄng Äáŧi thášĨp. ÄÃĒy là biášŋn cᚧn ÄÆ°áŧĢc Æ°u tiÊn quášĢn lÃ― và Äᚧu tÆ° Äáŧ
cášĢi thiáŧn kášŋt quášĢ.
COM và PRE cÅĐng ÄÃĄng chÚ Ã―, nhÆ°ng cᚧn chÚ Ã― táŧi Æ°u hÃģa máŧĐc Äáŧ khÃīng hiáŧu
quášĢ cáŧ§a chÚng (Äáš·c biáŧt là COM váŧi condition inefficiency 38.168%).
INN cÃģ máŧĐc khÃīng hiáŧu quášĢ cao nhášĨt cášĢ váŧ condition và outcome,
cᚧn xem xÃĐt lᚥi vai trÃē cáŧ§a biášŋn nà y trong mÃī hÃŽnh Äáŧ trÃĄnh lÃĢng phà nguáŧn láŧąc.
SIN cÃģ ášĢnh hÆ°áŧng thášĨp nhášĨt trong mÃī hÃŽnh (effect size = 0.194), nhÆ°ng nÃģ cÃģ máŧĐc
khÃīng hiáŧu quášĢ thášĨp, cho thášĨy biášŋn nà y khÃīng phášĢi là máŧt rà o cášĢn láŧn.
LÆ°u Ã―: VÃŽ CBI là biášŋn trung gian, nÊn khi kášŋt luášn CBI là biášŋn quan tráŧng nhášĨt thÃŽ chÚng ta cᚧn phÃĒn tÃch NCA tiášŋp táŧĨc váŧi mÃī hÃŽnh háŧi qui cÃēn lᚥi Äáŧ phÃĒn tÃch sÃĒu hÆĄn cho cÃĄc biášŋn ngoᚥi sinh trong mÃī hÃŽnh.
DÆ°áŧi ÄÃĒy là video hÆ°áŧng dášŦn phÃĒn tÃch NCA cáŧ§a Dr. Fawad, cÃĄc bᚥn cÃģ tháŧ tham khášĢo. Nášŋu cÃģ cÃĒu háŧi nà o cÃģ tháŧ liÊn háŧ tráŧąc tiášŋp váŧi tÃĄc giášĢ hoáš·c váŧi chÚng tÃīi.
Tà i liáŧu tham khášĢo (TášĢi tà i liáŧu tham khášĢo tᚥi ÄÃĒy â here)
Dul, J. (2016). Necessary condition analysis (NCA) logic and
methodology of ânecessary but not sufficientâ causality. Organizational
Research Methods, 19(1), 10â52.
Hair, J.F., Sarstedt, M., Ringle, C.M., and Gudergan, S.P.
(2024). Advanced Issues in Partial Least Squares Structural Equation
Modeling (PLS-SEM), 2nd Ed., Thousand Oaks, CA: Sage.
Richter, N.F., Hauff, S., Kolev, A.E., and Schubring, S.
(2023). Dataset On An
Extended Technology Acceptance Model: A Combined Application of PLS-SEM and NCA. Data
in Brief, 109190.
Richter, N.F., Hauff, S., Ringle, C.M., Sarstedt, M., Kolev, A., and Schubring, S. (2023). How to Apply Necessary Condition Analysis in PLS-SEM. In J. F. Hair, R. Noonan, and H. Latan (Eds.), Partial Least Squares Structural Equation Modeling: Basic Concepts, Methodological Issues and Applications (pp. 267-297). Springer: Cham. â Tà i liáŧu nà y sáš― khÃīng cÃģ trong tášp download, anh cháŧ nà o cᚧn thÃŽ liÊn háŧ váŧi chÚng tÃīi nhÃĐ!
Richter, N.F., Schubring, S., Hauff, S., Ringle, C.M., and Sarstedt, M. (2020). When Predictors of Outcomes are Necessary: Guidelines for the Combined use of PLS-SEM and NCA. Industrial Management & Data Systems, 120(12): 2243-2267.

Bà i Viášŋt LiÊn Quan.



