HÆŊáŧNG DᚊN PHÃN TÃCH
Mà HÃNH BᚎC HAI PLS SEM
SáŧŽ DáŧĪNG PHášĶN MáŧM SmartPLS
4
MÃī hÃŽnh bášc cao (higher-order model) là máŧt loᚥi mÃī hÃŽnh phÃĒn tÃch
cášĨu trÚc trong ÄÃģ cÃĄc biášŋn Äáŧc lášp và pháŧĨ thuáŧc ÄÆ°áŧĢc phÃĒn loᚥi và o cÃĄc nhÃģm, vÃ
máŧi nhÃģm ÄÆ°áŧĢc mÃī hÃŽnh hÃģa dÆ°áŧi dᚥng máŧt mÃī hÃŽnh cášĨu trÚc bášc nhášĨt (first-order
structural model). NhÃģm nà y sau ÄÃģ ÄÆ°áŧĢc sáŧ dáŧĨng là m biášŋn Äáŧc lášp trong máŧt mÃī
hÃŽnh cášĨu trÚc bášc cao.
Máŧt mÃī hÃŽnh bášc cao cÃģ tháŧ ÄÆ°áŧĢc xem nhÆ° là máŧt mÃī hÃŽnh phÃĒn tÃch cášĨu
trÚc bášc nhášĨt ÄÆ°áŧĢc máŧ ráŧng, váŧi nháŧŊng biášŋn Äáŧc lášp và pháŧĨ thuáŧc Äáš·c biáŧt ÄÆ°áŧĢc
nhÃģm lᚥi và mÃī hÃŽnh hÃģa dÆ°áŧi dᚥng máŧt mÃī hÃŽnh cášĨu trÚc bášc nhášĨt riÊng biáŧt. NháŧŊng
mÃī hÃŽnh bášc nhášĨt nà y ÄÆ°áŧĢc gáŧi là cÃĄc "mÃī hÃŽnh bášc dÆ°áŧi" (lower-order
models), trong khi mÃī hÃŽnh bášc cao cháŧĐa cÃĄc mÃī hÃŽnh bášc dÆ°áŧi nà y ÄÆ°áŧĢc gáŧi lÃ
"mÃī hÃŽnh bášc trÊn" (higher-order model).
MÃī hÃŽnh bášc cao ÄÆ°áŧĢc sáŧ dáŧĨng Äáŧ khášĢo sÃĄt máŧi quan háŧ giáŧŊa cÃĄc biášŋn áŧ
máŧĐc Äáŧ tráŧŦu tÆ°áŧĢng hÆĄn và pháŧĐc tᚥp hÆĄn, cung cášĨp cÃĄi nhÃŽn táŧng quÃĄt hÆĄn váŧ máŧi
quan háŧ giáŧŊa cÃĄc biášŋn. NÃģ thÆ°áŧng ÄÆ°áŧĢc sáŧ dáŧĨng trong cÃĄc nghiÊn cáŧĐu váŧ tÃĒm lÃ― háŧc,
giÃĄo dáŧĨc, kinh tášŋ háŧc và cÃĄc lÄĐnh váŧąc khoa háŧc xÃĢ háŧi khÃĄc Äáŧ khášĢo sÃĄt máŧi quan
háŧ giáŧŊa cÃĄc khÃĄi niáŧm tráŧŦu tÆ°áŧĢng.
Tuy nhiÊn, viáŧc sáŧ dáŧĨng mÃī hÃŽnh bášc cao ÄÃēi háŧi sáŧą am hiáŧu váŧ
phÆ°ÆĄng phÃĄp phÃĒn tÃch cášĨu trÚc và kinh nghiáŧm tháŧąc tášŋ Äáŧ xÃĄc Äáŧnh cÃĄc biášŋn Äáŧc
lášp và pháŧĨ thuáŧc thÃch háŧĢp Äáŧ nhÃģm lᚥi, và thiášŋt lášp máŧi quan háŧ giáŧŊa cÃĄc nhÃģm
biášŋn.
Äᚧu tiÊn Äáŧ Äi sÃĒu và o káŧđ thuášt phÃĒn tÃch mÃī hÃŽnh cášĨu trÚc bášc cao,
chÚng ta cᚧn nÃģi sÆĄ qua váŧ cÃĄc loᚥi mÃī hÃŽnh Äo lÆ°áŧng Äa hÆ°áŧng (multidimensional
measurement model).
MÃī hÃŽnh Äo lÆ°áŧng Äa hÆ°áŧng là máŧt loᚥi mÃī hÃŽnh trong phÃĒn tÃch Äo lÆ°áŧng,
trong ÄÃģ cÃĄc Äᚥi lÆ°áŧĢng ÄÆ°áŧĢc Äo lÆ°áŧng khÃīng cháŧ cÃģ máŧt chiáŧu mà cÃģ nhiáŧu chiáŧu,
hay cÃēn gáŧi là nhiáŧu thuáŧc tÃnh. Máŧt và dáŧĨ ÄÆĄn giášĢn váŧ mÃī hÃŽnh Äo lÆ°áŧng Äa hÆ°áŧng
là trong trÆ°áŧng háŧĢp Äo lÆ°áŧng cháŧ sáŧ phÃĄt triáŧn cáŧ§a máŧt quáŧc gia. Thay vÃŽ cháŧ Äo
lÆ°áŧng máŧt chiáŧu nhÆ° GDP, mÃī hÃŽnh Äo lÆ°áŧng Äa hÆ°áŧng sáš― Äo lÆ°áŧng nhiáŧu chiáŧu nhÆ°
GDP, chášĨt lÆ°áŧĢng giÃĄo dáŧĨc, tuáŧi tháŧ, ÄÃĄnh giÃĄ sáŧĐc kháŧe... Trong mÃī hÃŽnh Äo lÆ°áŧng
Äa hÆ°áŧng, cÃĄc Äᚥi lÆ°áŧĢng ÄÆ°áŧĢc Äo lÆ°áŧng ÄÆ°áŧĢc xÃĄc Äáŧnh dÆ°áŧi dᚥng cÃĄc biášŋn tiÊn
ÄoÃĄn và ÄÆ°áŧĢc mÃī hÃŽnh hÃģa bášąng mÃī hÃŽnh SEM (Structural Equation Modeling) hoáš·c
PLS (Partial Least Squares). Äiáŧu nà y cho phÃĐp phÃĒn tÃch quan háŧ giáŧŊa cÃĄc thuáŧc
tÃnh và tÃŽm ra cÃĄc máŧi quan háŧ tiáŧm ášĐn giáŧŊa cÃĄc thuáŧc tÃnh.
Theo
Äáŧi váŧi biášŋn tiáŧm ášĐn phášĢn ÃĄnh (reflective constructs) là máŧt loᚥi biášŋn trong ÄÃģ biášŋn ÄÆ°áŧĢc Äo lÆ°áŧng (observed variables) ÄÆ°áŧĢc coi là phášĢn ÃĄnh (reflect) máŧt biášŋn tiáŧm ášĐn (latent variable).
Trong mÃī hÃŽnh reflective, cÃĄc
biášŋn latents (cÅĐng ÄÆ°áŧĢc gáŧi là factors) ÄÆ°áŧĢc cho là phášĢn ÃĄnh cÃĄc khÃa cᚥnh, chiáŧu
cáŧ§a máŧt biášŋn ášĐn chung. CÃĄc biášŋn quan sÃĄt (observed variables) ÄÆ°áŧĢc coi là phášĢn
ÃĄnh hoáš·c Äo lÆ°áŧng cÃĄc biášŋn latents nà y. Äiáŧu quan tráŧng là cÃĄc biášŋn quan sÃĄt phášĢi
cÃģ sáŧą tÆ°ÆĄng quan mᚥnh váŧi biášŋn latents mà chÚng Äo lÆ°áŧng. CÃĄc biášŋn quan sÃĄt
khÃīng ÄÆ°áŧĢc cho là cÃģ ášĢnh hÆ°áŧng lášŦn nhau hoáš·c cÃģ ÄÃģng gÃģp và o viáŧc xÃĄc Äáŧnh biášŋn
latents.
KhÃĄc váŧi biášŋn tiáŧm ášĐn phášĢn ášĢnh (reflective constructs), biášŋn tiáŧm ášĐn cášĨu trÚc (formative constructs) là máŧt loᚥi biášŋn trong phÃĒn tÃch SEM (Structural Equation Modeling), trong ÄÃģ biášŋn Äo lÆ°áŧng (observed variables) ÄÆ°áŧĢc coi là Äáŧnh hÃŽnh (form) máŧt biášŋn tiáŧm ášĐn (latent variable).
TrÃĄi ngÆ°áŧĢc váŧi mÃī hÃŽnh
reflective, trong mÃī hÃŽnh formative, cÃĄc biášŋn quan sÃĄt ÄÆ°áŧĢc cho là tᚥo nÊn hoáš·c
hÃŽnh thà nh biášŋn latents. Äiáŧu nà y cÃģ nghÄĐa là cÃĄc biášŋn quan sÃĄt ášĢnh hÆ°áŧng Äášŋn
biášŋn latents và ÄÃģng gÃģp và o viáŧc xÃĄc Äáŧnh chÚng. Do vášy mà nhà nghiÊn cáŧĐu khÃīng tháŧ loᚥi báŧ Äi máŧt biášŋn quan sÃĄt nà o cáŧ§a biášŋn tiáŧm ášĐn loᚥi nà y. Trong mÃī hÃŽnh formative, cÃĄc
biášŋn quan sÃĄt khÃīng ÄÆ°áŧĢc cho là cÃģ tÆ°ÆĄng quan mᚥnh váŧi nhau hoáš·c váŧi biášŋn
latents.
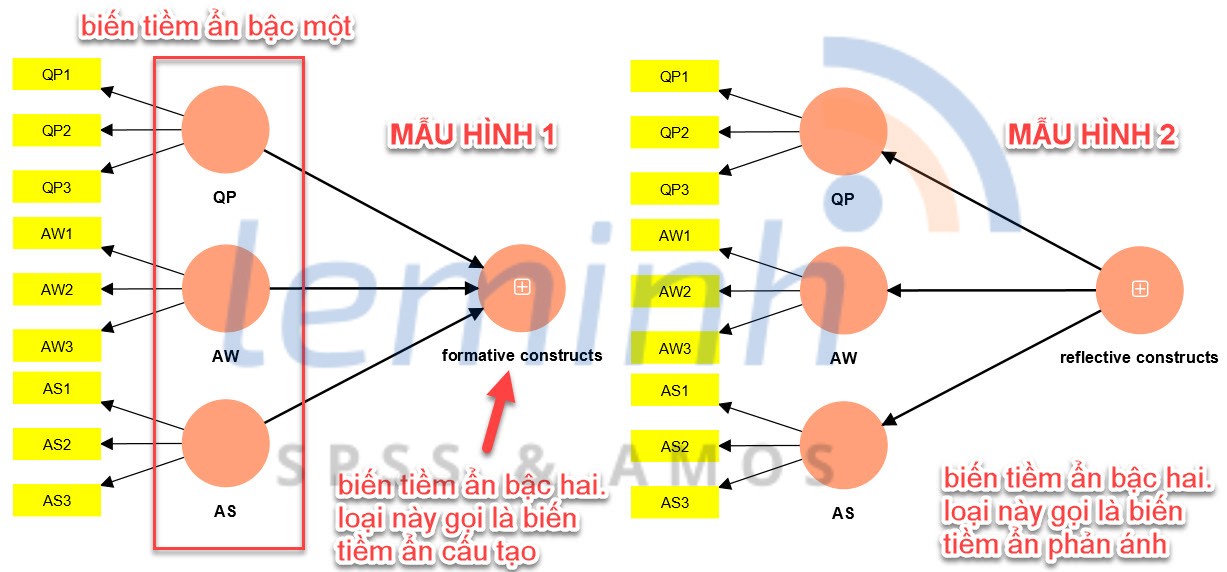
Trong mášŦu hÃŽnh 1 và mášŦu hÃŽnh 2, chÚng ta Äáŧi chiáŧu mÅĐi tÊn áŧ cÃĄc cháŧ
bÃĄo cáŧ§a biášŋn tiáŧm ášĐn bášc máŧt sáš― ÄÆ°áŧĢc thÊm hai mášŦu hÃŽnh máŧi, nhÆ°ng hai loᚥi nà y Ãt
ÄÆ°áŧĢc sáŧ dáŧĨng, nÊn áŧ ÄÃĒy chÚng ta sáš― khÃīng xem xÃĐt táŧi.
NhÆ° vášy trÆ°áŧc khi phÃĒn tÃch PLS SEM, anh cháŧ cᚧn xÃĄc lášp ÄÆ°áŧĢc hÃŽnh mášŦu mÃī hÃŽnh nghiÊn cáŧĐu dáŧąa trÊn cÃĄc cÆĄ sáŧ lÃ― thuyášŋt náŧn váŧŦa nÊu áŧ trÊn kášŋt háŧĢp váŧi máŧĨc tiÊu nghiÊn cáŧĐu và tà i liáŧu tham khášĢo táŧŦ cÃĄc nghiÊn cáŧĐu trÆ°áŧc. NÃģi thÊm, sáŧą láŧąa cháŧn giáŧŊa mÃī hÃŽnh reflective và mÃī hÃŽnh formative pháŧĨ thuáŧc và o Ã― nghÄĐa lÃ― thuyášŋt và cÆĄ sáŧ dáŧŊ liáŧu cáŧ§a nghiÊn cáŧĐu. Äiáŧu quan tráŧng là ÄášĢm bášĢo rášąng sáŧą láŧąa cháŧn phÃđ háŧĢp váŧi máŧĨc tiÊu nghiÊn cáŧĐu và tÃnh chášĨt cáŧ§a cÃĄc biášŋn ÄÆ°áŧĢc nghiÊn cáŧĐu. LÆ°u Ã― rášąng viáŧc xÃĄc Äáŧnh mÃī hÃŽnh reflective hoáš·c formative khÃīng phášĢi lÚc nà o cÅĐng ÄÆĄn giášĢn, và cÃģ tháŧ ÄÃēi háŧi sáŧą cÃĒn nhášŊc káŧđ lÆ°áŧĄng và kiášŋn tháŧĐc váŧ lÄĐnh váŧąc nghiÊn cáŧĐu cáŧĨ tháŧ.
ChÚng ta sáš― cÃģ 2 cÃĄch Äáŧ tháŧąc hiáŧn mÃī hÃŽnh PLS SEM bášc cao, cášĢ hai cÃĄch Äáŧu giáŧng nhau áŧ giai Äoᚥn 2, cháŧ khÃĄc nhau áŧ giai Äoᚥn 1. Giai Äoᚥn 1 là chÚng ta sáš― Äi tÃŽm cháŧ bÃĄo cho biášŋn tiáŧm ášĐn bášc cao.
CÃĄch tháŧĐ nhášĨt là chÚng ta tᚥo ra biášŋn bášc hai áŧ tᚥi giai Äoᚥn máŧt bášąng cÃĄch ÄÆ°a tášĨt cášĢ cÃĄc cháŧ bÃĄo cáŧ§a biášŋn bášc máŧt và o nhÆ° hÃŽnh.
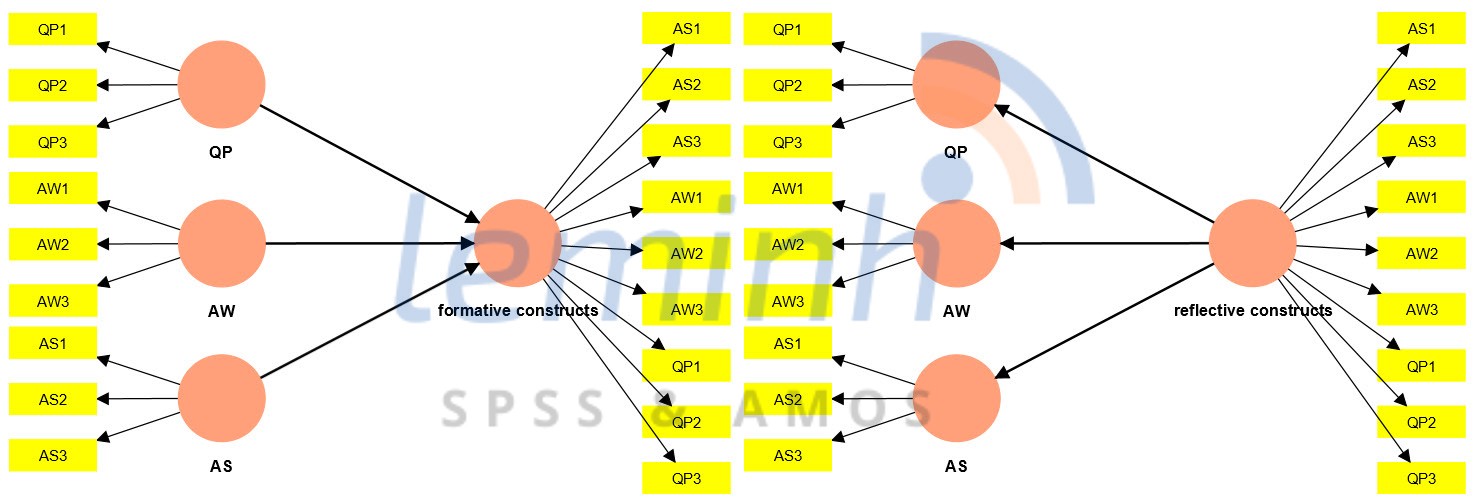
Viáŧc ÄÃĄnh giÃĄ mÃī hÃŽnh áŧ giai Äoᚥn máŧt nà y cᚧn tháŧąc hiáŧn ÄÃĄnh giÃĄ cÃĄc cháŧ tiÊu váŧ máŧĐc Äáŧ tin cášy, máŧĐc Äáŧ chÃnh xÃĄc váŧ sáŧą háŧi táŧĨ, và máŧĐc Äáŧ chÃnh xÃĄc váŧ sáŧą phÃĒn biáŧt. CÃĄch ÄÃĄnh giÃĄ chÚng ta ÄÃĢ Äáŧ cášp trong cÃĄc bà i viášŋt trÆ°áŧc ÄÃģ nÊn áŧ ÄÃĒy sáš― khÃīng trÃŽnh bà y lᚥi.
Trong trÆ°áŧng háŧĢp mÃī hÃŽnh áŧ giai Äoᚥn máŧt khÃīng Äᚥt yÊu cᚧu, chÚng ta cᚧn tiášŋn hà nh xáŧ lÃ― lᚥi dáŧŊ liáŧu theo cÃĄc cÃĄch:
+ Loᚥi báŧ cÃĄc quan sÃĄt (Observed variables) khÃīng ÄášĢm bášĢo cÃĄc Äiáŧu kiáŧn áŧ trÊn và tiášŋn hà nh chᚥy lᚥi táŧŦ Äᚧu.
+ NghiÊn cáŧĐu lᚥi bášĢng háŧi (questionnaire) và tháŧąc hiáŧn khášĢo sÃĄt lᚥi.
+ LiÊn háŧ váŧi Dáŧch váŧĨ sáŧ liáŧu LÊ Minh Äáŧ ÄÆ°áŧĢc háŧ tráŧĢ nhanh chÃģng.
NÃģi thÊm, vášĨn Äáŧ loᚥi báŧ biášŋn quan sÃĄt ra kháŧi thang Äo cᚧn hášŋt sáŧĐc cÃĒn nhášŊc trÆ°áŧc khi quyášŋt Äáŧnh. ChÚng tÃīi khuyášŋn cÃĄo cÃĄc bᚥn nÊn tham khášĢo thÊm Ã― kiášŋn cáŧ§a NgÆ°áŧi hÆ°áŧng dášŦn khoa háŧc Äáŧ tháŧąc hiáŧn.
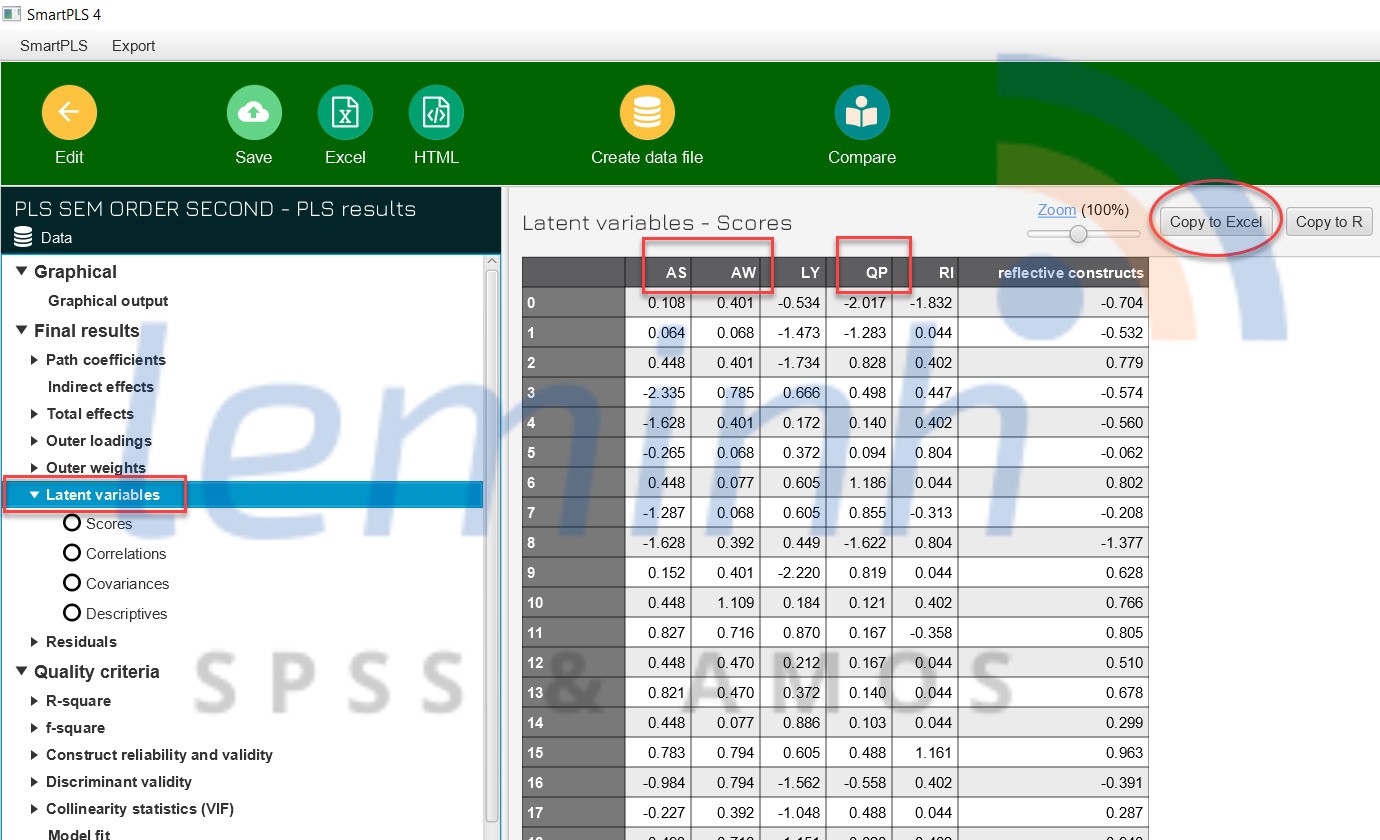
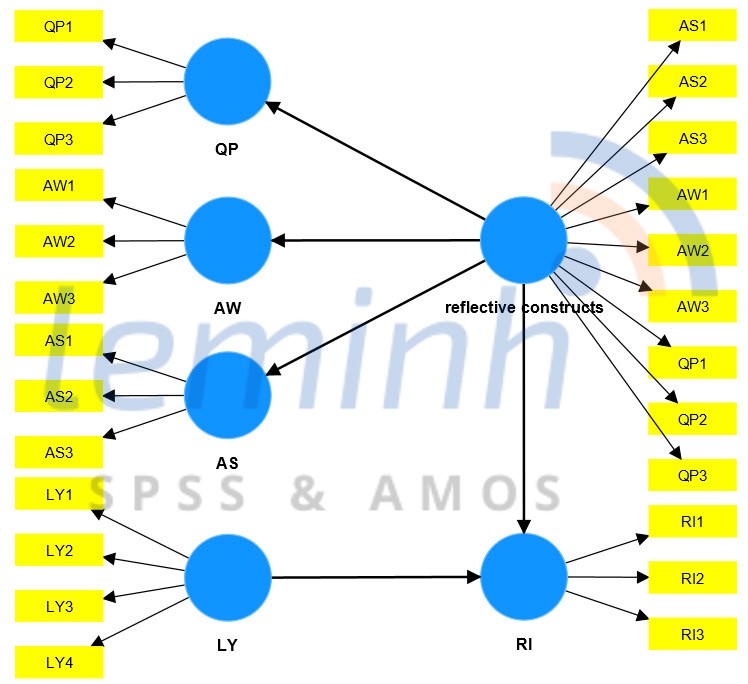
Nášŋu mÃī hÃŽnh áŧ giai Äoᚥn máŧt Äᚥt yÊu cᚧu, chÚng ta sáš― Äi tÃŽm cÃĄc cháŧ bÃĄo cho biášŋn tiáŧm ášĐn bášc hai bášąng cÃĄch nhášĨn và o Open report cháŧn Latent variables và copy dáŧŊ liáŧu sang file excel. áŧ file excel nà y, chÚng ta sáš― cÃģ cÃĄc cháŧ bÃĄo cho biášŋn bášc hai, trong và dáŧĨ nà y là AS, AW và QP.
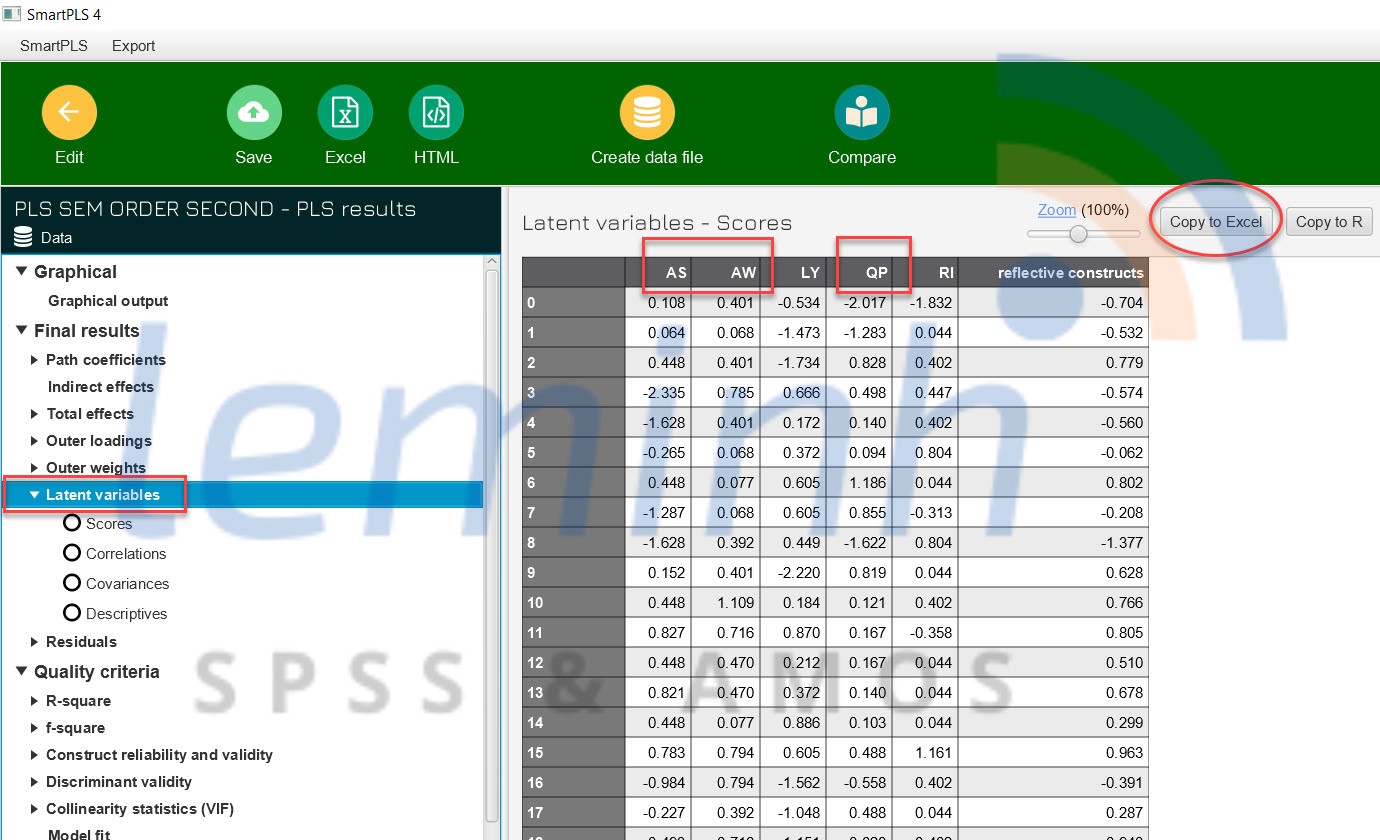
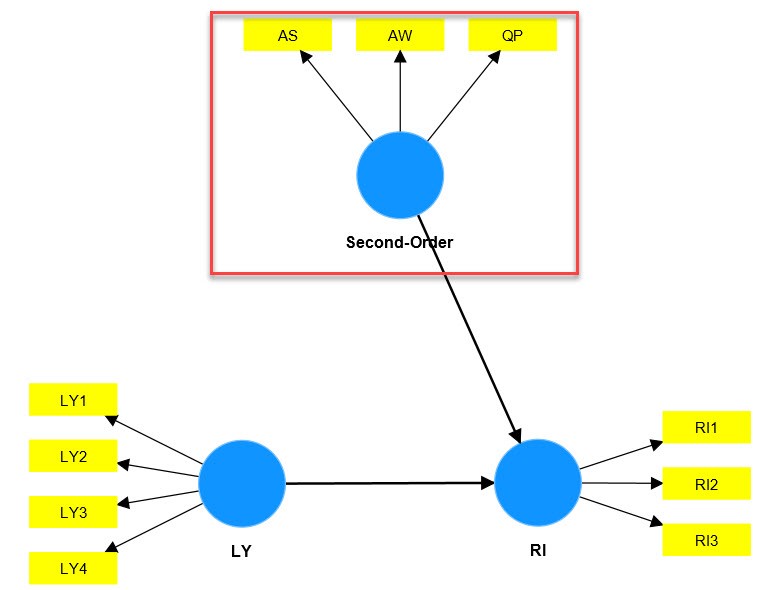
LÚc nà y mÃī hÃŽnh bášc hai ÄÆ°áŧĢc xÃĒy dáŧąng lᚥi nhÆ° sau, giai Äoᚥn nà y ÄÆ°áŧĢc xem là giai Äoᚥn 2. ChÚng ta lÆ°u Ã―, nÊn lÆ°u data thà nh máŧt file khÃĄc và chÃĻn và o SmartPLS Äáŧ sáŧ dáŧĨng cho mÃī hÃŽnh bášc hai.
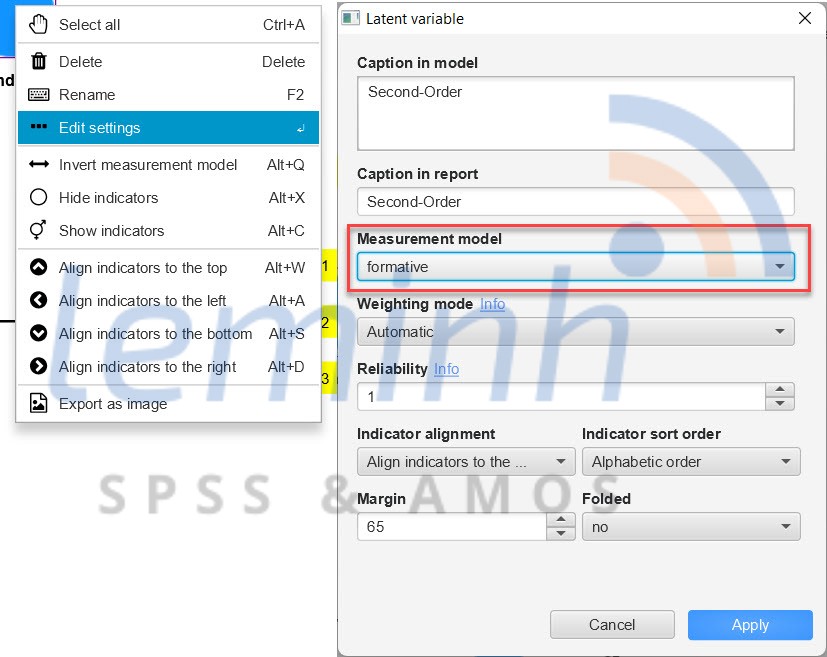
Äáŧi váŧi mÃī hÃŽnh cášĨu tᚥo, Äáŧ thay Äáŧi mÅĐi tÊn chÚng ta click chuáŧt phášĢi và o biášŋn bášc hai (Second-Order) và cháŧn Edit settings, áŧ mÃī hÃŽnh Äo lÆ°áŧng cháŧn formative nhÃĐ.
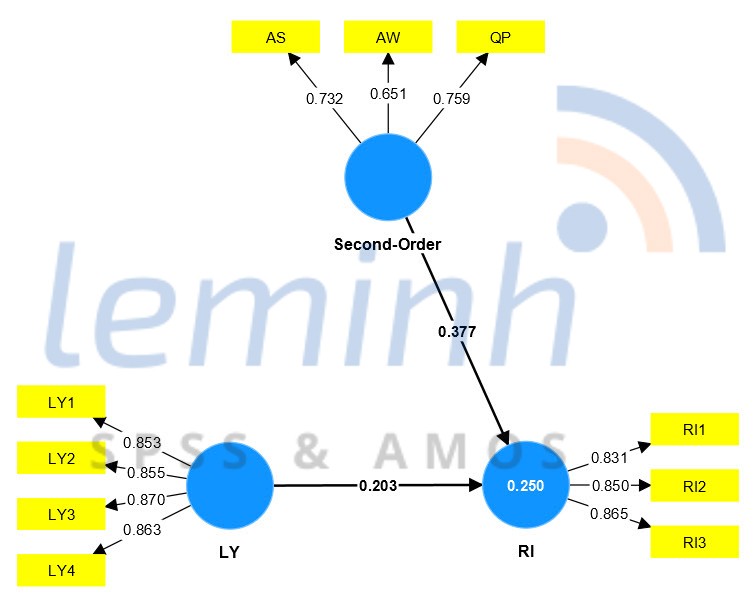
NghiÊn cáŧĐu sáš― kášŋt luášn giášĢ thuyášŋt nghiÊn cáŧĐu dáŧąa trÊn kášŋt quášĢ cáŧ§a mÃī hÃŽnh áŧ giai Äoᚥn hai. PhÃĒn tÃch bootstrapping Äáŧ kiáŧm tra p value.
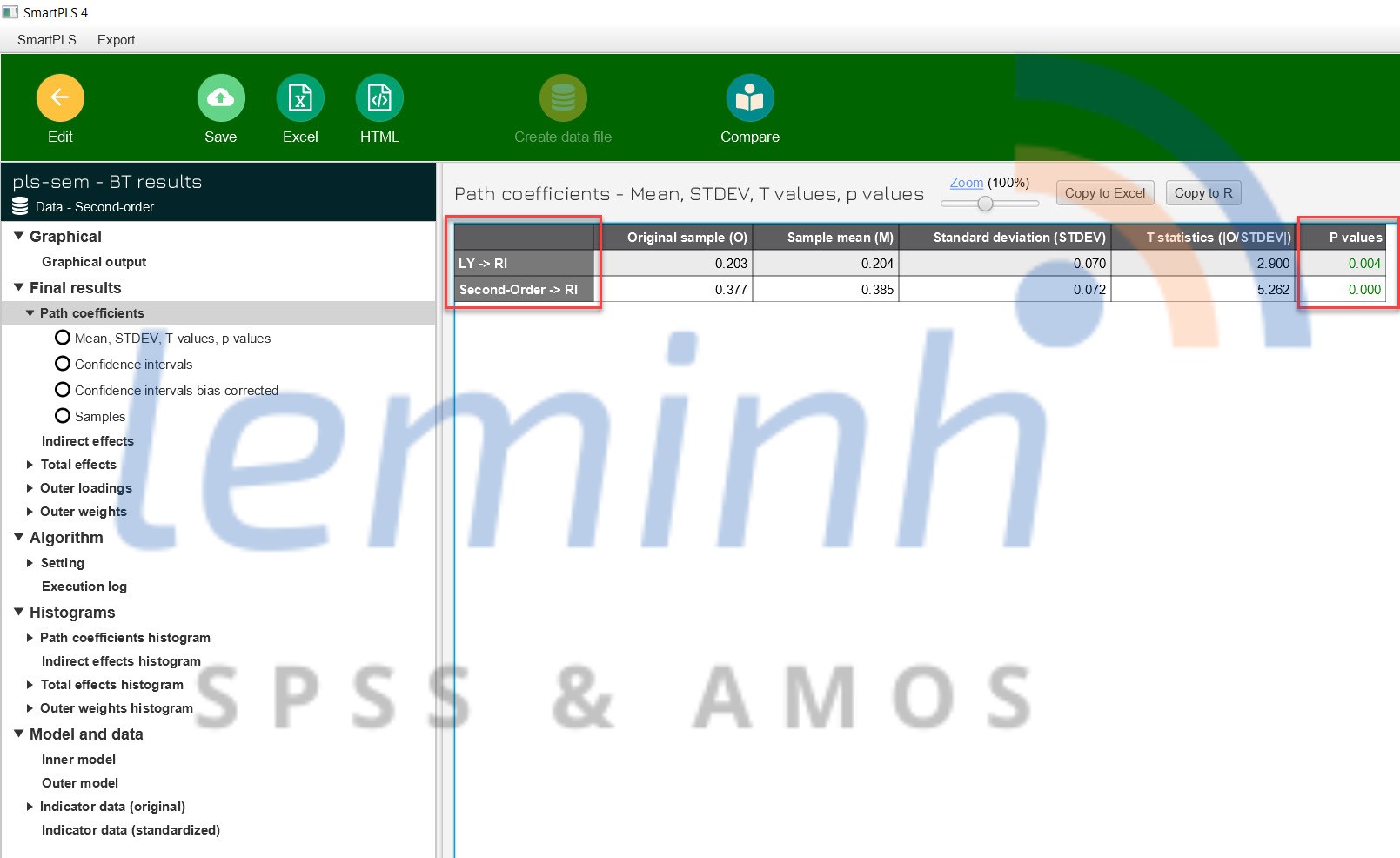
áŧ ÄÃĒy cášĢ 2 giášĢ thuyášŋt nghiÊn cáŧĐu Äáŧu ÄÆ°áŧĢc chášĨp nhášn. VášĨn Äáŧ cÃēn lᚥi là thášĢo luášn kášŋt quášĢ nghiÊn cáŧĐu và ÄÆ°a ra cÃĄc giášĢi phÃĄp khuyášŋn ngháŧ nášŋu cÃģ. LÆ°u Ã―, khi thášĢo luášn kášŋt quášĢ Äáŧ ÄÆ°a khuyášŋn ngháŧ cᚧn xem xÃĐt kášŋt háŧĢp váŧi kášŋt quášĢ cÃĄc cháŧ bÃĄo cáŧ§a biášŋn tiáŧm ášĐn áŧ giai Äoᚥn máŧt.
Anh cháŧ cÃģ tháŧ tham khášĢo tà i liáŧu SmartPLS áŧ hai cuáŧn sÃĄch nà y cáŧ§a GS. Nguyáŧ n Minh Hà (Äᚥi háŧc Máŧ Tp HCM). Trong cášĢ hai cuáŧn nà y GS cháŧ tháŧąc hà nh trÊn SmartPLS 3. CÃēn phiÊn bášĢn SmartPLS 4 hiáŧn tᚥi cháŧ cÃģ máŧt cuáŧn tiášŋng Anh cáŧ§a tÃĄc giášĢ Chua Yan Plaw (cuáŧn nà y anh cháŧ cÃģ tháŧ mua trÊn amazone, giÃĄ ÄÃĒu ÄÃģ khoášĢng trÊn dÆ°áŧi 2tr gÃŽ ÄÃģ).

KÃnh chÚc cÃĄc anh cháŧ hoà n thà nh táŧt nghiÊn cáŧĐu cáŧ§a mÃŽnh. Nášŋu anh cháŧ cᚧn xáŧ lÃ― dáŧŊ liáŧu liÊn quan SmartPLS, anh cháŧ cÃģ tháŧ tham khášĢo dáŧch váŧĨ áŧ ÄÃĒy.
LÆ°u Ã― thÊm, Äáŧi máŧi mÃī hÃŽnh cášĨu trÚc bášc cao, tÃĄc giášĢ Collier (2020) lÆ°u Ã― váŧi ngÆ°áŧi Äáŧc chi tiášŋt nhÆ° sau:


Bà i Viášŋt LiÊn Quan.



