GIáŧI THIáŧU COMMON METHOD VARIANCE (CMV) - CÃCH NHᚎN DIáŧN Và PHÃNG TRÃNH
CMV là gÎ?
Common method variance (CMV) hay phÆ°ÆĄng sai do phÆ°ÆĄng phÃĄp chung â là hiáŧn tÆ°áŧĢng xášĢy ra khi máŧt yášŋu táŧ liÊn quan Äášŋn cÃĄch Äo lÆ°áŧng ášĢnh hÆ°áŧng Äášŋn toà n báŧ cÃĄc ÄÃĄnh giÃĄ trong nghiÊn cáŧĐu. CMV thÆ°áŧng xuášĨt hiáŧn khi cÃĄc biášŋn ÄÆ°áŧĢc thu thášp bášąng cÃđng máŧt phÆ°ÆĄng phÃĄp hoáš·c táŧŦ cÃđng máŧt nguáŧn dáŧŊ liáŧu, chášģng hᚥn nhÆ° khi tášĨt cášĢ cÃĄc cÃĒu háŧi khášĢo sÃĄt ÄÆ°áŧĢc Äáš·t cÃđng lÚc, theo máŧt Äáŧnh dᚥng giáŧng nhau, và táŧŦ cÃđng máŧt ngÆ°áŧi trášĢ láŧi.
Cᚧn là m gÃŽ Äáŧ trÃĄnh CMV?
Theo Change và cáŧng sáŧą (2010), cÃģ 4 cÃĄch Äáŧ giášĢm
thiáŧu hoáš·c trÃĄnh CMV cho dáŧŊ liáŧu Äᚧu và o trong nghiÊn cáŧĐu, ÄÃģ là :
1. XÃĒy dáŧąng thang Äo báŧi nhiáŧu nguáŧn thÃīng tin khÃĄc
nhau (Äa dᚥng nguáŧn dáŧŊ liáŧu sáŧ dáŧĨng Äáŧ xÃĒy dáŧąng thang Äo). Change và cáŧng sáŧą
(2010) khuyášŋn cÃĄo rášąng, thang Äo cáŧ§a cÃĄc biášŋn Äáŧc lášp nÊn sáŧ dáŧĨng nguáŧn thÃīng
tin khÃĄc váŧi biášŋn pháŧĨ thuáŧc. CÃĄc cÃĒu háŧi ÄÆ°áŧĢc Äáš·t ra máŧt cÃĄch ÄÆĄn giášĢn, ngášŊn gáŧn,
dáŧ
hiáŧu, khÃīng nÊn sáŧ dáŧĨng cÃĄc thuášt ngáŧŊ khÃģ hiáŧu, cÃĄc thuášt ngáŧŊ chuyÊn ngà nh sáš―
là m cho ngÆ°áŧi ÄÆ°áŧĢc khášĢo sÃĄt mÆĄ háŧ, khÃīng hiáŧu nghÄĐa và táŧŦ ÄÃģ ÄÆ°a ra cÃĄc láŧąa cháŧn
khÃīng chÃnh xÃĄc.
2. BášĢng háŧi khášĢo sÃĄt nÊn xÃĄo tráŧn tháŧĐ táŧą cÃĄc cÃĒu háŧi
(Äiáŧu nà y táŧt cho viáŧc loᚥi báŧ CMV, tuy nhiÊn cÃģ máŧt nhÆ°áŧĢc Äiáŧm là sáš― là m dÃĄn
Äoᚥn dÃēng suy nghÄĐ cáŧ§a ngÆ°áŧi trášĢ láŧi trong cÃđng máŧt thang Äo). Sáŧ dáŧĨng cÃĄc loᚥi
thang Äo khÃĄc nhau, sáŧ dáŧĨng cÃĄc biášŋn kiáŧm soÃĄt Äáŧ kiáŧm tra ngÆ°áŧi ÄÆ°áŧĢc khášĢo sÃĄt
cÃģ thášt sáŧą nášŊm thÃīng tin và trášĢ láŧi chÃnh xÃĄc cÃĒu háŧi hay khÃīng. Máŧt Äiáŧu quan
tráŧng là tÃnh bášĢo mášt trong thÃīng tin cáŧ§a ngÆ°áŧi trášĢ láŧi, Äiáŧu nà y giÚp cho ÄÃĄp
viÊn trášĢ láŧi máŧt cÃĄch thà nh thášt, và táŧŦ ÄÃģ giášĢm ÄÆ°áŧĢc CMV.
3. Thiášŋt kášŋ nghiÊn cáŧĐu cášŊt ngang (cross-sectional
design) sáš― giÚp cho ngÆ°áŧi ÄÆ°áŧĢc khášĢo sÃĄt nášŊm rÃĩ hÆĄn tÃŽnh hÃŽnh hiáŧn tᚥi cáŧ§a sášĢn
phášĐm hay dáŧch váŧĨ, và ÄÆ°a ra cÃĄc cÃĒu trášĢ láŧi chÃnh xÃĄc hÆĄn.
4. Ãp dáŧĨng phÆ°ÆĄng phÃĄp phÃĒn tÃch nhÆ° kiáŧm Äáŧnh
Harman's one-factor Äáŧ kiáŧm tra và Äiáŧu cháŧnh CMV.
ChÚng ta nÊn kášŋt háŧĢp tášĨt cášĢ cÃĄc biáŧn phÃĄp trÊn lÃ
cÃĄch táŧt nhášĨt Äáŧ giášĢm thiáŧu hoáš·c trÃĄnh CMV trong nghiÊn cáŧĐu.
Thiášŋt kášŋ nghiÊn cáŧĐu cášŊt ngang (cross-sectional
design) (cÃēn gáŧi là nghiÊn cáŧĐu táŧ· láŧ hiáŧn hà nh, hay tᚧn suášĨt lÆ°u hà nh) là máŧt
phÆ°ÆĄng phÃĄp thu thášp dáŧŊ liáŧu trong nghiÊn cáŧĐu khoa háŧc, trong ÄÃģ dáŧŊ liáŧu ÄÆ°áŧĢc
thu thášp tᚥi máŧt tháŧi Äiáŧm cáŧĨ tháŧ táŧŦ máŧt nhÃģm ngÆ°áŧi hoáš·c cÃĄc Äáŧi tÆ°áŧĢng nghiÊn cáŧĐu.
Thiášŋt kášŋ nà y cho phÃĐp nhà nghiÊn cáŧĐu thu thášp thÃīng tin váŧ cÃĄc biášŋn quan sÃĄt tᚥi
máŧt tháŧi Äiáŧm duy nhášĨt và phÃĒn tÃch máŧi quan háŧ giáŧŊa chÚng.
Nhášn diáŧn CMV
Theo Tehseen và cáŧng sáŧą (2017) cÃģ 4 phÆ°ÆĄng phÃĄp xÃĄc Äáŧnh CMV. ÄÃģ là :
1. Kiáŧm Äáŧnh Harmanâs Single-Factor
2. Partial Correlation Procedures
(i)
Partialling Out of General Factor
(ii)
Partialling Out a Marker Variable (Lindell & Whitney, 2001)
(iii)
Partialling Out a âMarkerâ Variable (Podsakoff et al., 2003)
3. Correlation Matrix Procedure
4. The Measured Latent Marker Variable Approach
(i)
Construct Level Correction (CLC) Approach
(ii) Item
level correction (ILC) Approach
Trong ÄÃģ, phÆ°ÆĄng phÃĄp sáŧ 4 ÄÆ°áŧĢc khuyášŋn ngháŧ sáŧ dáŧĨng
sau khi phÃĒn tÃch cÃĄc mÃī hÃŽnh Äo lÆ°áŧng và mÃī hÃŽnh cášĨu trÚc Äáŧ quan sÃĄt tÃĄc Äáŧng cáŧ§a CMV
Äáŧi váŧi giÃĄ tráŧ R2 và háŧ sáŧ ÄÆ°áŧng dášŦn. CÅĐng nÃģi thÊm váŧi cÃĄc bᚥn, cÃĄc phÆ°ÆĄng
phÃĄp nà y dÃđng Äáŧ xÃĄc Äáŧnh cÃģ hay khÃīng cÃģ CMV trong dáŧŊ liáŧu nghiÊn cáŧĐu cháŧĐ
khÃīng tháŧ khášŊc pháŧĨc hay loᚥi tráŧŦ CMV ra kháŧi dáŧŊ liáŧu nghiÊn cáŧĐu.
áŧ ÄÃĒy chÚng tÃīi xin trÃŽnh bà y 2 cÃĄch Äáŧ nhášn diáŧn
CMV trong dáŧŊ liáŧu nghiÊn cáŧĐu. CÃĄch tháŧĐ nhášĨt tháŧąc hiáŧn kiáŧm Äáŧnh Harman's one-factor bášąng SPSS, và cÃĄch tháŧĐ hai là tháŧąc hiáŧn Partial Correlation Procedures bášąng SmartPLS.
I. HÆ°áŧng dášŦn tháŧąc hiáŧn kiáŧm Äáŧnh Harman's one-factor bášąng
SPSS
ÄÃĒy là máŧt kiáŧm Äáŧnh pháŧ biášŋn nhášĨt ÄÆ°áŧĢc cÃĄc nhÃ
nghiÊn cáŧĐu tháŧąc hiáŧn Äáŧ kiáŧm tra CMV trong cÃĄc nghiÊn cáŧĐu cáŧ§a háŧ. PhÃĒn tÃch Harman's
one-factor là máŧt tháŧ§ táŧĨc post hoc ÄÆ°áŧĢc tiášŋn hà nh sau khi thu thášp dáŧŊ liáŧu
Äáŧ kiáŧm tra xem liáŧu máŧt yášŋu táŧ duy nhášĨt cÃģ cháŧu trÃĄch nhiáŧm cho sáŧą khÃĄc biáŧt
trong dáŧŊ liáŧu hay khÃīng (Chang và cáŧng sáŧą, 2010). Trong phÆ°ÆĄng phÃĄp nà y, tášĨt cášĢ
cÃĄc biášŋn quan sÃĄt Äo lÆ°áŧng cho cÃĄc thang Äo trong mÃī hÃŽnh nghiÊn cáŧĐu Äáŧu ÄÆ°áŧĢc
ÄÆ°a và o phÃĒn tÃch nhÃĒn táŧ Äáŧ kiáŧm tra xem liáŧu máŧt nhÃĒn táŧ duy nhášĨt cÃģ xuášĨt hiáŧn
hay liáŧu máŧt nhÃĒn táŧ chung duy nhášĨt cÃģ dášŦn Äášŋn phᚧn láŧn hiáŧp phÆ°ÆĄng sai giáŧŊa
cÃĄc thÆ°áŧc Äo hay khÃīng; nášŋu khÃīng cÃģ yášŋu táŧ ÄÆĄn lášŧ nà o xuášĨt hiáŧn và chiášŋm phᚧn
láŧn hiáŧp phÆ°ÆĄng sai, Äiáŧu nà y cÃģ nghÄĐa là CMV khÃīng phášĢi là vášĨn Äáŧ pháŧ biášŋn
trong nghiÊn cáŧĐu (Chang và cáŧng sáŧą, 2010). Sáŧ dáŧĨng phÃĒn tÃch nhÃĒn táŧ trong SPSS
Äáŧ tháŧąc hiáŧn kiáŧm Äáŧnh nà y. CÃĄc bÆ°áŧc sau ÄÃĒy ÄÆ°áŧĢc tháŧąc hiáŧn khi tiášŋn hà nh tháŧ
nghiáŧm nà y:
(1) Nhášp tášĨt cášĢ cÃĄc items và o phÃĒn tÃch nhÃĒn táŧ và chᚥy phÃĒn tÃch thà nh phᚧn chÃnh.
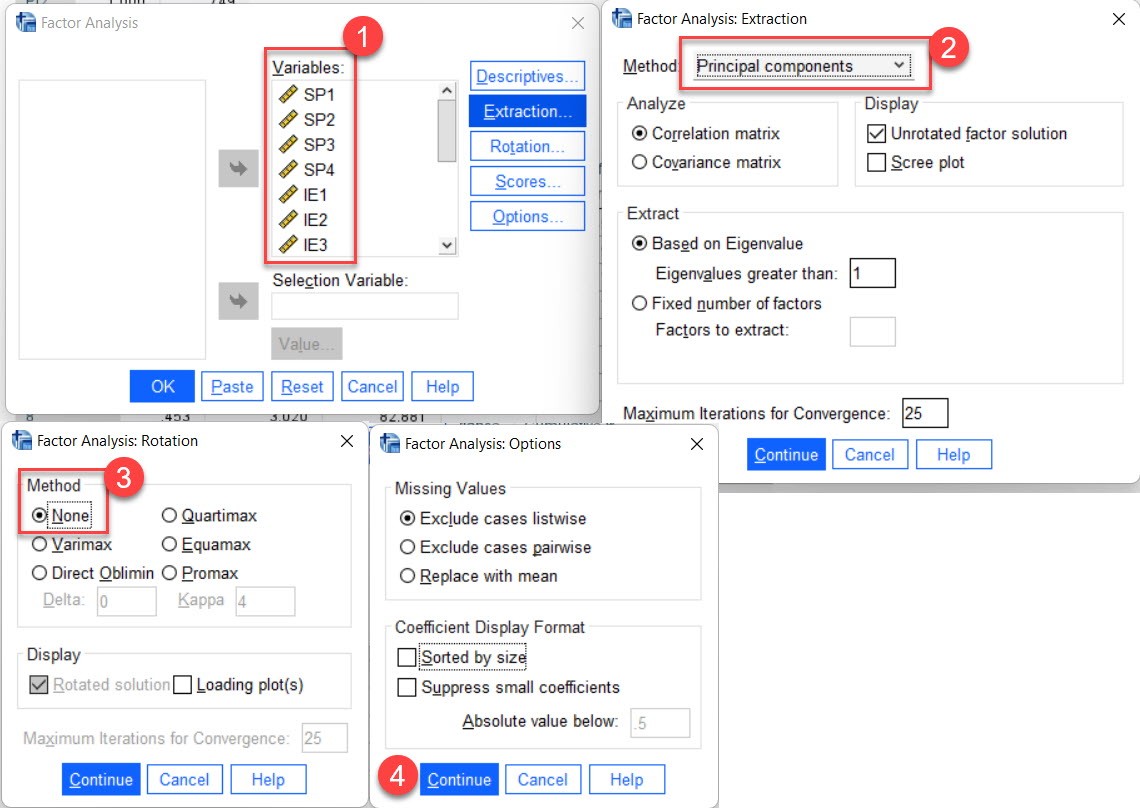
(2) Kiáŧm tra phÆ°ÆĄng sai cáŧ§a thà nh phᚧn Äᚧu tiÊn nášŋu nháŧ hÆĄn 50% (theo Hair (2019, p744) thÃŽ âĪ 40%) thÃŽ kášŋt luášn khÃīng cÃģ CMV.
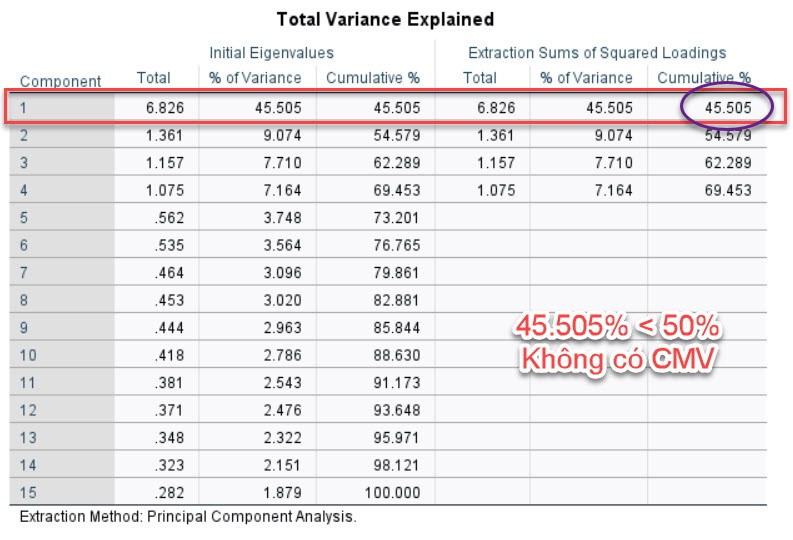
Trong trÆ°áŧng háŧĢp chÚng ta chᚥy CB SEM bášąng AMOS, chÚng tÃīi khuyášŋn ngháŧ cÃĄc bᚥn nÊn tháŧąc hiáŧn thÊm tháŧ§ táŧĨc kiáŧm Äáŧnh Äáŧ phÃđ háŧĢp cáŧ§a mÃī hÃŽnh cášĨu trÚc ÄÆĄn yášŋu táŧ. TrÆ°áŧng háŧĢp model fit thášĨp thÃŽ cháŧĐng táŧ rášąng, CMV khÃīng phášĢi là Äiáŧu ÄÃĄng lo ngᚥi trong mÃī hÃŽnh nghiÊn cáŧĐu cáŧ§a bᚥn. CÃģ tháŧ tham khášĢo thÊm Hautala-KankaanpÃĪÃĪ (2022).
II. HÆ°áŧng dášŦn tháŧąc hiáŧn Partial Correlation Procedures
Äáŧ kiáŧm tra CMV bášąng SmartPLS
Äᚧu tiÊn, chÚng ta sáš― tᚥo ra biášŋn General factor bášąng cÃĄch tᚥo dáŧŊ liáŧu random cho biášŋn nà y.
ChÚng ta sáš― tᚥo ra máŧi tÆ°ÆĄng quan giáŧŊa biášŋn General factor váŧi biášŋn pháŧĨ thuáŧc trong mÃī hÃŽnh. Sau ÄÃģ xem xÃĐt R2 cáŧ§a biášŋn pháŧĨ thuáŧc trÆ°áŧc và sau khi thÊm biášŋn General factor, nášŋu R2 cÃģ sai khÃĄc nhiáŧu thÃŽ kášŋt luášn cÃģ hiáŧn tÆ°áŧĢng CMV trong dáŧŊ liáŧu nghiÊn cáŧĐu, và ngÆ°áŧĢc lᚥi. LÆ°u Ã―, váŧi mÃī hÃŽnh cÃģ nhiáŧu biášŋn pháŧĨ thuáŧc thÃŽ tᚥo thÊm cÃĄc máŧi quan háŧ giáŧŊa biášŋn pháŧĨ thuáŧc và biášŋn General factor.
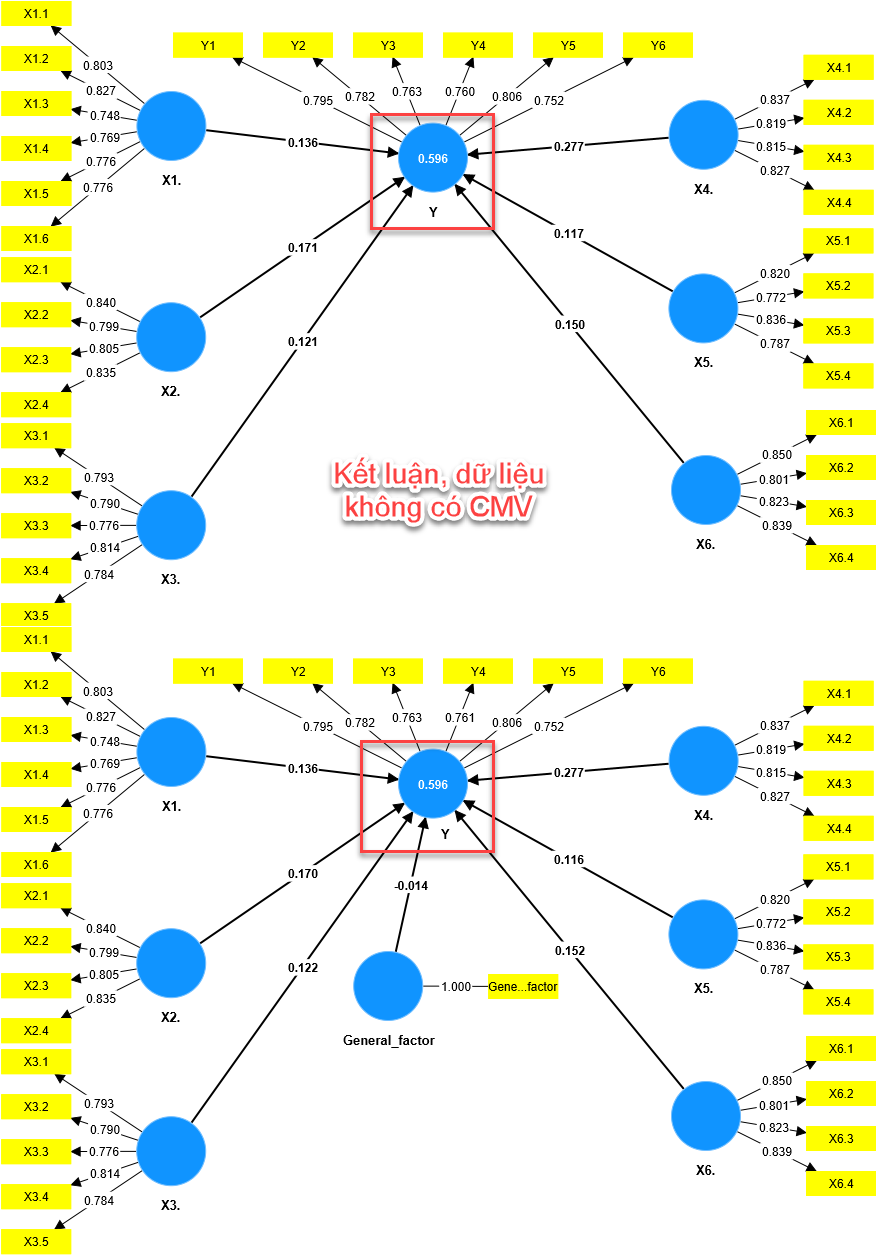
III. Tiášŋp theo, chÚng tÃīi hÆ°áŧng dášŦn cÃĄc anh cháŧ kiáŧm tra CMV Äáŧi váŧi nháŧŊng mÃī hÃŽnh pháŧĐc tᚥp sáŧ dáŧĨng SmartPLS. PhÆ°ÆĄng phÃĄp nà y ÄÆ°áŧĢc Kock và Lynn (2012) giáŧi thiáŧu, và Kock (2015) ÄÆ°a ra máŧĐc VIFs âĪ 3.3.
ChÚng ta
chuyáŧn mÃī hÃŽnh qua dᚥng ÄÆĄn nhÃĒn táŧ bášąng cÃĄch sáŧ dáŧĨng giÃĄ tráŧ biášŋn tiáŧm ášĐn (latent
variables).
Äᚧu tiÊn, phÃĒn tÃch mÃī hÃŽnh gáŧc, lášĨy giÃĄ tráŧ biášŋn tiáŧm ášĐn, và tᚥo thÊm biášŋn General factor.
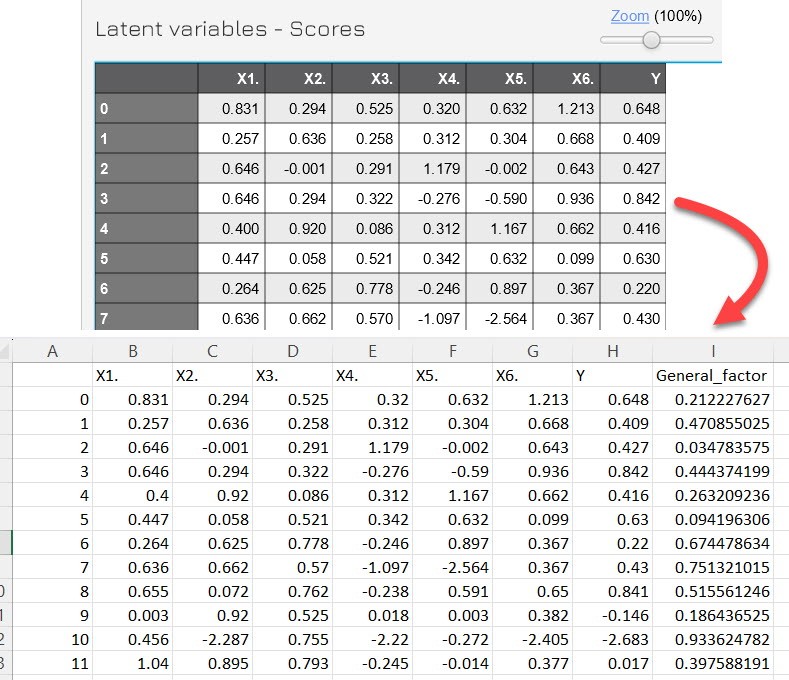
MÃī hÃŽnh lᚥi theo dᚥng single factor.
Äáŧc phÃĒn tÃch, chÚng ta kiáŧm tra giÃĄ tráŧ VIF cáŧ§a mÃī hÃŽnh biášŋn náŧi sinh (biášŋn náŧi sinh là biášŋn cÃģ mÅĐi tÊn hÆ°áŧng và o, áŧ ÄÃĒy là biášŋn General factor). Nášŋu giÃĄ tráŧ VIF nà y nháŧ hÆĄn 3.3 thÃŽ kášŋt luášn khÃīng cÃģ CMV (CMB).
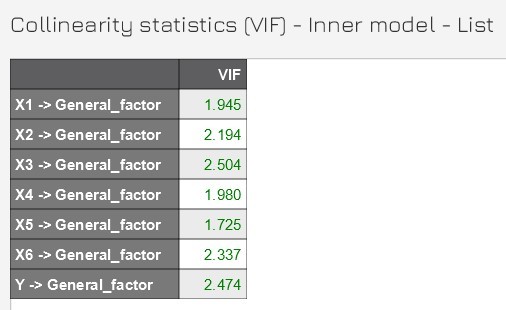
Kášŋt quášĢ cho thášĨy dáŧŊ liáŧu nghiÊn cáŧĐu khÃīng cÃģ CMV. CÃĄc bᚥn cÃģ tháŧ tham khášĢo thÊm video hÆ°áŧng dášŦn tháŧąc hà nh loᚥi nà y cáŧ§a Dr. Ashulekha Gupta tᚥi ÄÃĒy.
TÃ i liáŧu tham khášĢo
Change, S., Witteloostuijn, A. V, & Eden, L. (2010). From the editors: Common method variance in international research. Journal of International Business Studies, 41(2), 178â184.
Hair, J. F., Black, W.
C., Babin, B. J., & Anderson, R. E. (2019). Multivariate data analysis .
Cengage Learning. Hampshire, United Kingdom.
Hautala-KankaanpÃĪÃĪ, T. (2022). The impact of
digitalization on firm performance: examining the role of digital culture and
the effect of supply chain capability. Business Process Management
Journal, 28(8), 90â109.
Kock, N. (2015). Common method bias in PLS-SEM: A full collinearity assessment approach. International Journal of E-Collaboration (Ijec), 11(4), 1â10.
Kock, N., & Lynn, G. (2012).
Lateral collinearity and misleading results in variance-based SEM: An
illustration and recommendations. Journal of the Association for Information
Systems, 13(7).
Lindell, M. K., & Whitney, D. J. (2001).
Accounting for common method variance in cross-sectional research designs. Journal
of Applied Psychology, 86(1), 114.
Podsakoff, P. M., MacKenzie, S. B., Lee,
J.-Y., & Podsakoff, N. P. (2003). Common method biases in behavioral
research: a critical review of the literature and recommended remedies. Journal
of Applied Psychology, 88(5), 879.
Tehseen, S., Ramayah, T., & Sajilan, S. (2017). Testing and controlling for common method variance: A review of available methods. Journal of Management Sciences, 4(2), 142â168.

Bà i Viášŋt LiÊn Quan.



